I wrote a live repl for imp and made a demo video. I think this is one of those things where a quantitive change in speed makes a qualitative difference - in theory this is just a slightly faster way to type things into a repl, but in practice it feels totally different. Pointing at a thing to query it feels very natural.
To make the live repl experience work better I made a lot of changes to the syntax so that it requires far fewer backwards motions while typing (eg to add a parenthesis around an expression) and is much more compact.
Before:
let rightmost_child = edits (?edit . edit .
(max [edit ~parent])) in
let rightmost_leaf =
fix none (?[rightmost_leaf] .
edits (?edit . edit .
(max [edit | (edit rightmost_leaf rightmost_child)])))) in
let prev_sibling = edits (?edit . edit
(max [(edit parent ~parent) (?sibling . (when (edit > sibling) sibling))])) in
let prev = edits (?edit . edit .
if !!(prev_sibling edit)
([prev_sibling edit] max rightmost_leaf)
(edit parent)) in
let position =
fix none (?[position] .
edits (?edit . edit .
if !(edit parent) then 0 else
(edit prev position) + 1)) in
edits (?edit .
(edit position) . edit . (edit character))
After:
rightmost_child: edits.?edit edit parent~ @ max;
fix rightmost_leaf: edits.?edit edit | edit rightmost_child rightmost_leaf @ max;
prev_sibling: edits.?edit edit parent parent~ .(?sibling edit > sibling) @ max;
prev: edits.?edit edit prev_sibling !! then edit prev_sibling rightmost_leaf else edit parent;
fix position: root, 0 | edits.?edit (edit prev position) + 1;
edits ?edit (edit position), edit, (edit character)
There is also some crude error recovery in parsing, as demonstrated near the end of the demo video. I'd like to find a more systematic way of doing this, so that the program can be evaluated at every point during typing.
The interpreter gained a number of new abilities to support this demo. It now reports the source location of compile-time and run-time errors, it supports setting limits on memory usage and can be safely interrupted from another thread. The imp library includes all the code needed for running the interpreter in a background thread and coordinating changes to the source program.
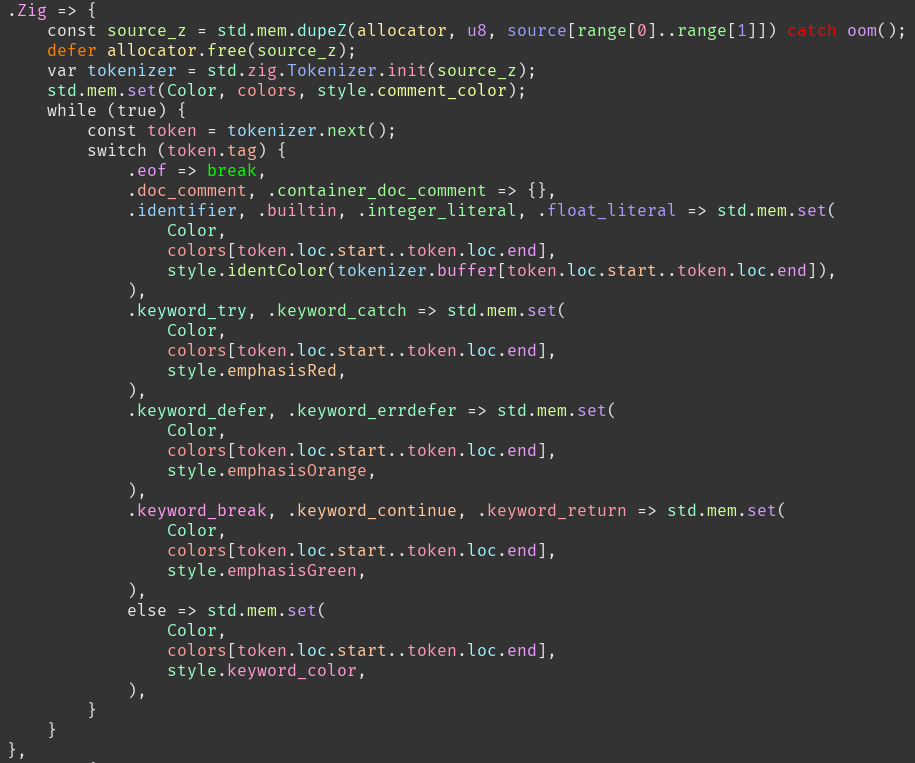
The text editor in the demo is focus. To support the demo I added error squigglies and syntax highlighting for imp. I also added syntax highlighting for zig, since that's where I spend most of my time.
I couldn't find any rationale for supporting one syntax highlighting scheme over another (although Hillel Wayne's rant on the subject has many good suggestions.)
For now I'm giving a different color to each identifier, to make it easy to visually scan code for uses of a given variable, or to at-a-glance see the differences between two similar lines. I generate the colors in HSL space with the hue chosen based on the hash of the identifier and set them all to the same lightness so that none jump out over the others. I also experimented with varying the saturation to get more distinct colors, but as the saturation gets lower it's harder to distinguish different hues so in the end it seemed best to set saturation to maximum.
In zig, I hardcode the colors for try/catch, defer/errdefer and return/break/continue and use a higher lightness value, so that these control-flow altering keywords pop out.
Dida has had a few bugfixes but still has some major known bugs. I haven't put any more time yet into the debugger.
For a long time I intended to put the imp live repl on the web so that it's easy to try it out. But the web is such a monstrous pile of complexity and arbitary limitations that it presents a huge energy barrier to any project. My main bottleneck is always motivation and writing webapps is a death by a thousand cuts. So I've decided that all of the imp tooling is going to be native for the forseeable future.
The same logic applies to the dida debugger, except that putting the explanation of how dida works on the web is kind of a hard requirement for the project. So maybe I'll struggle through that one.
I freed these posts from draft limbo:
I'm hoping to write more of the focus posts at some point. I like the idea of having a text editor with a small codebase and some narrative document explaining the reasoning behind everything, as a way to demystify the subject.
I've been playing with the alpha for rel. I'm not allowed to say anything about it yet. But definitely keep an eye on it.
I mentioned in the last news post that I've been talking to someone at oracle about updating their documentation on decorrelating subqueries.
In the last month I asked for an up-to-date description of the current capabilities and limitations. They replied that it can now decorrelate any subquery except those which are not possible to decorrelate correctly, giving an example. I demonstrated that both cockroachdb and materialize decorrelate the example correctly. I've not heard from them since so maybe that's not going to go anywhere.
Last month I bemoaned the lack of crafting interpreters -style book for databases.
Vegard Stikbakke pointed me towards ChiDB
chidb is a didactic relational database management system (RDBMS) designed for teaching how a RDBMS is built internally, from the data organization in files all the way up to the SQL parser and query optimizer. The design of chidb is based on SQLite, with several simplifying assumptions that make it possible to develop a complete chidb implementation over the course of a quarter or semester. One of the key similarities is that chidb uses a single file to store all its information (database metadata, tables, and indexes). In fact, the chidb file format is a subset of SQLite, meaning that well-formed chidb files will also be well-formed SQLite files (the opposite, though, is not necessarily true).
This is exactly what I wanted.
I also found The Design and Implementation of Modern Column-Oriented Database Systems and Database Internals. I have no idea how good either of them are, but seems worth a look.
I talked a while ago about the pinebook pro - a $200 arm laptop that would be a fantastic machine but for the nigh-unusable touchpad. A recent firmware update dramatically improved the touchpad and I can now recommend it unreservedly.
This comment by Tyler Neely is great.
This is generally why complex systems tend to get crappier and crappier over time - people will 'improve' small aspects by increasing utilization of resources rather than improving efficiency to get the desired gains, causing less resources to be available to other consumers of compute resources, and making the overall system worse in ways that are difficult to detect when monitoring something other than realistic overall workloads on realistic hardware.
One of the links is Scylla's Approach to Improve Performance for CPU-bound workloads
A very handy tool for collecting and analyzing data provided by the PMU is toplev. It employs the Top-Down Analysis, which uses a hierarchical representation of the processor architecture to keep track of pipeline slots. This enables tools like toplev to show the percentages of slots the were stalled, wasted by bad speculation or used by a successfully retired instruction.
academia is a lousy place to do novel research
Our Machinery continues to routinely solve problems with immediate-mode guis that are regularly asserted to be impossible. This month it's accessibility.
The Handmade Network is having a Wheel Reinvention Jam.
The Wheel Reinvention Jam is a one-week-long jam where you create a replacement for a program that frustrates you.
Maybe it's a common utility that always breaks. Maybe it's a slow, bloated program that does too much for its own good. Or maybe it's a program that never caught on because the design was too confusing. Whatever the case, this is your chance to replace it with something new.
The rules for the jam are flexible. You can participate alone or with a team, and for as much of the time as your schedule allows. And there's no winner - our goal is to kickstart meaningful projects of all kinds.
Rui Ueyama has many great projects. I'm particularly excited by chibicc:
chibicc is developed as the reference implementation for a book I'm currently writing about the C compiler and the low-level programming. The book covers the vast topic with an incremental approach; in the first chapter, readers will implement a "compiler" that accepts just a single number as a "language", which will then gain one feature at a time in each section of the book until the language that the compiler accepts matches what the C11 spec specifies. I took this incremental approach from the paper by Abdulaziz Ghuloum.
Each commit of this project corresponds to a section of the book. For this purpose, not only the final state of the project but each commit was carefully written with readability in mind. Readers should be able to learn how a C language feature can be implemented just by reading one or a few commits of this project. For example, this is how while, [], ?:, and thread-local variable are implemented. If you have plenty of spare time, it might be fun to read it from the first commit.
Gordon Brander writes about how files tend towards supporting interop between different systems, while the web tends towards silos.
Files mean the OS can guarantee basic rights for your data. On the web, 'data' is a miasma, invisibly collected, transferred, leaked, and shared. In the desktop paradigm, 'data' is a document, a physical object you can manipulate. All documents can be moved, copied, shared or deleted, whether or not an app implements these features.
A survey of parsers used by major language implementations.
Spoiler - they're almost all handwritten. But we continue to teach students primarily using parser generators.
Denis Bakhvalov of easyperf fame release a free online course on performance engineering.
In this course, you will practice analyzing and improving performance of your application. It is not a course on algorithms and data structures. Instead, we focus on low-level CPU-specific performance issues, like cache misses, branch mispredictions, etc.
I don't know what they want from it, how they can be satisfied with the petty round of grant money, publication, and prizes. Whereas I have always known, deep down. I wanted things I saw only dimly - fluids that glowed, and electricity that arced and danced like a living thing. I wanted science inside of me, changing me, my body as a generator, as a reactor, a crucible. Transformation, transcendence. And so, of course, they called me mad.
I remember those nights, planning technologies that didn't exist yet, outsider science, futurist dreaming, half-magical. The things I could do outside the university setting, now that I didn't have to wait for the pompous fools at the college! I was building another science, my science, wild science, robots and lasers and disembodied brains. A science that buzzed and glowed; it wanted to do things. It could get up and walk, fly, fight, sprout garish glowing creations in the remotest parts of the world, domes and towers and architectural fever dreams. And it was angry. It was mad science.