New stuff:
- In dida:
- I added a global validation routine that runs on every debug event. So far it detects any unintended aliasing. I'll test other invariants as needed.
- I wrote a debugger (video, code). This is my first time using dear imgui and I'm really impressed - it took only a few hours to write the first version and much of that was learning curve. It was at least an order of magnitude less effort than making a web app.
- Armed with these new tools I fixed some major bugs:
- Joins now correctly track the past state of their input indexes rather than always using the latest version. This prevents double-counting under some schedule orders, as well as several weirder bugs.
- There was a temporary change list during the execution of Reduce/Distinct that did not coalesce changes. As a result, it was possible for it to grow exponentially wrt to the number of inputs. That section of code has been restructured to avoid needing the temporary list at all.
- There were several instances of undefined behavior in
deepClonefrom silly typos. These were caught by the validation routine.
- Dida now produces the correct answers for the example problem that I used in Internal consistency in streaming systems, on which both flink sql and ksqldb produce a stream of incorrect answers.
- In focus:
- I made the maker tool robust to invalid output and have it kill it's children on each reset to avoid orphaned processes.
- Various perf improvements for the selector widget. I can now open the zig repo (13.6k files, 3.5m lines) and search for 'e' (2.3m results) without dropping any frames.
- Added some code to run child processes asynchronously (for the maker tool and for ripgrep). Maybe interesting is that I'm still avoiding callbacks in this codebase, so the code is instead based on polling and this actually made it much easier to handle cancellation correctly.
- Myriad small bugfixes.
- I also updated imp, dida and focus to the latest version of zig. There were some changes to the way namespaces work which required a large number of trivial edits.
- More reflections:
- After the success with dear imgui I tried porting a small julia script to zig using implot. The c api for implot is unpleasant and zig doesn't have any libraries yet for csv or dates so this wasn't a great experience, but implot itself seems promising. I was also pleasantly surprised to find out that the zig version actually manages quicker feedback loops - even when loading code in the repl the julia compilation time is still worse.
- I've been experimenting with virtual coworking after reading Alexey Guzey's report. So far it seems useful, but I'll try it for a few months before drawing any conclusions.
- It looks like I may have started a conference. It was just a spurious coffee thought but several people immediately volunteered to help organize so I guess we're doing this now. The rough theme is 'short demo videos of weird and non-traditional uses of database ideas' eg writing a dvcs in sql or building a game engine around a shared database. It will be online only, likely some time around March-May. I'm still figuring out the details but please email me if you think you would want to submit a demo, or if you've run a conference before and want to tell me all the things not to do.
I virtually went to Handmade Seattle. Some of the highlights:
- A practical guide to applying data-oriented design by Andy Kelley. Working through some examples of changes he's made to the zig compiler in search of better performance. Nothing new if you've been following his work so far, but it's a very accessible intro.
- Whitebox was as impressive as ever (last years talk is a better place to start if you didn't see it). This year brought linux support!
- I'm not much interested in game dev but Randy Gauls talk featured a demo of using coroutines instead of state machines to implement complex modal UIs that got me thinking.
- Nushell is a shell that uses a simple nested relational algebra instead of strings, allowing you to type things like
ls | where size > 1kb | sort-by modified. With examples like that it's hard not to see bash' mess of string parsing as embarrassing. - I wasn't expecting much from medc but it ended up being the most innovative and clever takes on text editing that I've seen in years.
- Roc is a pure functional language with some interesting choices - a structural type system, no boxing for most types, defunctionalization of closures, using reference counting to allow mutating data-structures when they have no other owners. I'm not particularly excited about the language itself, especially given the elm heritage, but it will be interesting to see if this approach to performance works out.
- The interview with Our Machinery wasn't very exciting but it reminded me how good their blog is. See for example the list of posts here (broken link, no archive) about the UI library they built for their game engine tools.
Also from last months Wheel Reinvention Jam, this cute sql gui has a lot of nice little touches like being able to snap nodes together to keep the graph tidy.
Randy Gauls coroutine gui demo reminded me how nice the airtable scripting api is.
Here's a silly little script that renames records:
let table = base.getTable("Menu");
let record = await input.recordAsync('Select a menu item', table);
if (record) {
let new_name = await input.textAsync('New name');
await table.updateRecordAsync(record, {Name: new_name});
}
I pop open the script editor and type in that code.
I couldn't get a screenshot of the autocomplete because it disappears when the window loses focus, but when editing the {Name: ...} it knows that it should be a record from the Menu table so it autocompletes the columns and types for that table. I'm not even sure how they're doing that - did they extend the typescript inference to look at the database schema whenever it sees base.getTable with a constant argument?
I hit run and it looks like this:

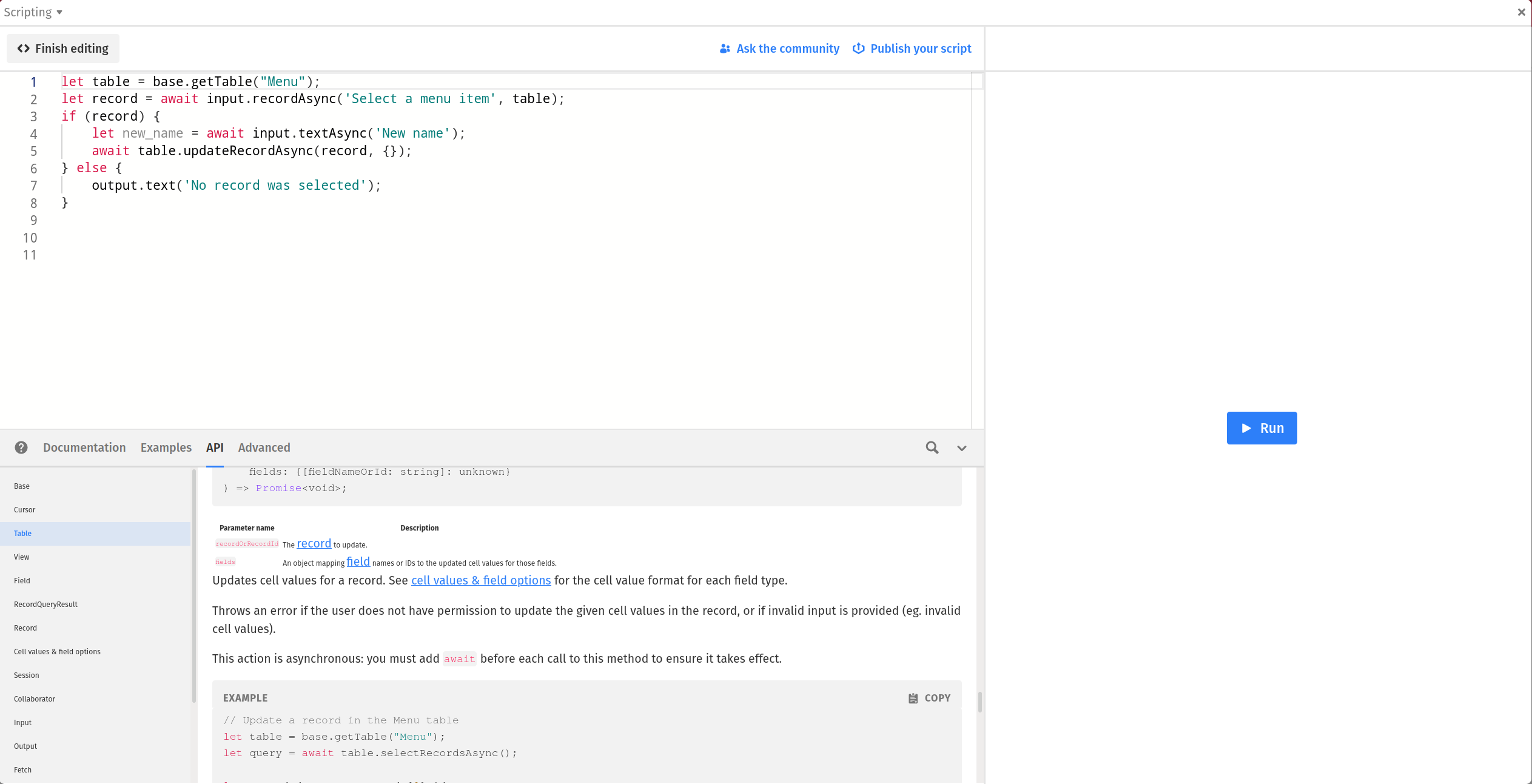
It reaches the input.recordAsync and suspends the script there, waiting for the user to pick a record from this gorgeous autocomplete:
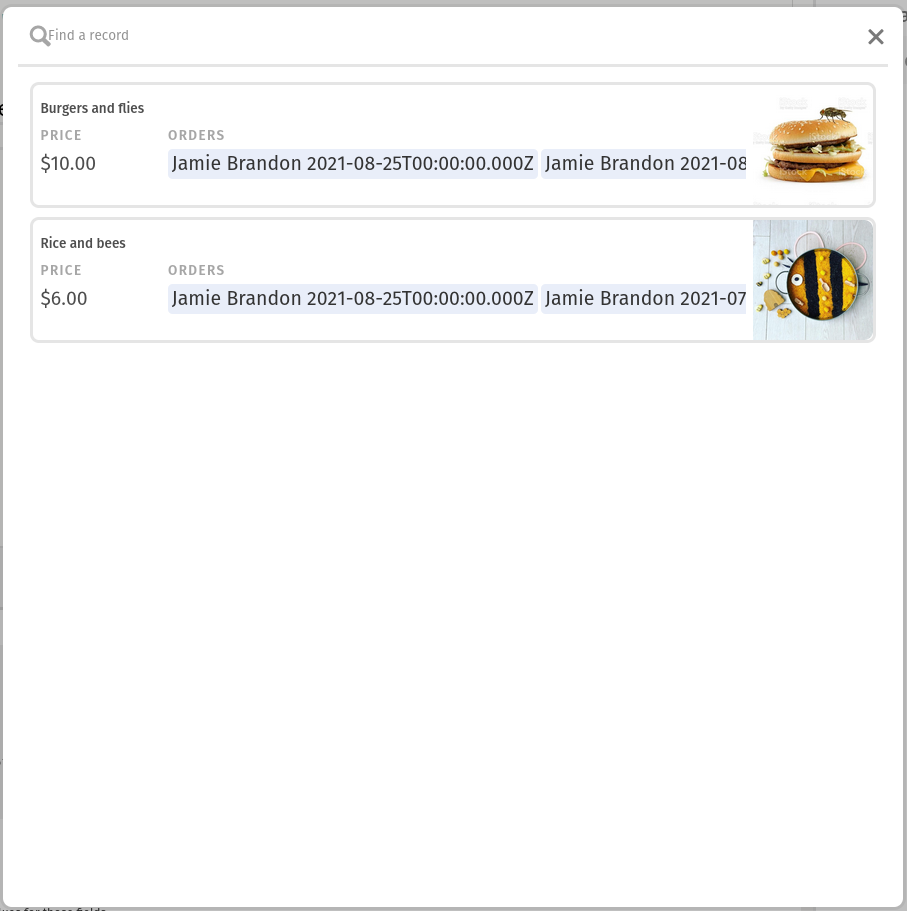
Once the record has been picked the script resumes and creates a text input:
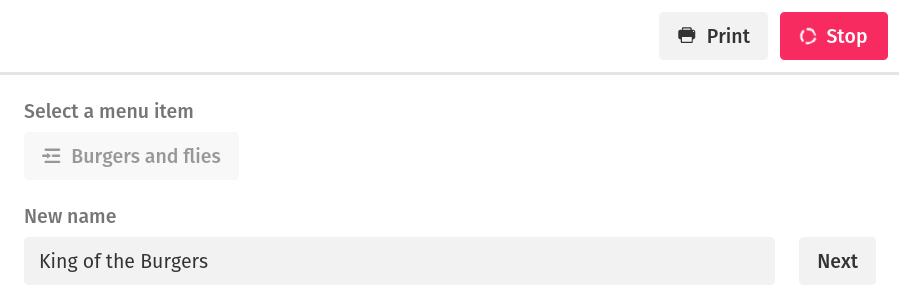
The whole thing took me a couple of minutes from a standing start. I've never seen anything else that approached this level of ease for writing plugins.
An oral history of Bank Python
Note how the same themes crop up as in airtable: a builtin editor, a single source of data, automatic deployment of code etc.
Napa: Powering Scalable Data Warehousing with Robust Query Performance at Google
Napa decouples ingestion from view maintenance, and view maintenance from query processing. This decoupling provides clients knobs to meet their requirements, allowing tradeoffs among freshness, performance, and cost.
Similar internal data model to DD. Seems like Spanner takes the place of DDs point-stamp exchange.
Disappointing that they didn't go into more detail on how they manage consistency during view updates. Maybe they just propagate updates in arbitary order and only withhold the final output? If so, it would seem like they could see internal consistency violations when querying beyond the QT.
I'm continually annoyed by how static site generators rely on anaemic template languages, and by how markdown limits the kinds of structures I can use for writing. I really like the idea behind pollen - just define a way to embed some real language directly into arbitrary text files. This can serve as a replacement for markdown, as a template language for html and css and as a scripting language for assembling derived state like rss feeds.
Markdown:
◊title{We don't need no markdown!}
Here is some ◊link{python}{https://www.python.org/} code:
◊(require pollen/unstable/pygments)
◊highlight['python]{
for x in range(3):
print x
}
And some math:
◊(define ($ . xs)
`(mathjax ,(apply string-append `("$" ,@xs "$"))))
◊(define ($$ . xs)
`(mathjax ,(apply string-append `("$$" ,@xs "$$"))))
◊h1{I wonder if ◊${2^{\aleph_\alpha} = \aleph_{\alpha+1}}?}
HTML:
◊(define (important text) (div #:class "red" #:style "font-size:150%" text))
<html>
<body>
◊(->html doc)</body>
<footer>
◊important{Do ◊em{NOT} press the red button}
</footer>
</html>
CSS:
◊(define inner 2)
◊(define edge (* inner 2))
◊(define color "gray")
◊(define multiplier 1.3)
body {
margin: ◊|edge|em;
border: ◊|inner|em double ◊|color|;
padding: ◊|inner|em;
font-size: ◊|multiplier|em;
line-height: ◊|multiplier|;
}
h1 {
font-size: ◊|multiplier|em;
}
#prev, #next {
position: fixed;
top: ◊|(/ edge 2)|em;
}
#prev {
left: ◊|edge|em;
}
#next {
right: ◊|edge|em;
}
I'm not about to run out and rewrite my blog in racket, but I bet I could embed js or imp in a similar way...
Related - how documentation could be better and how markdown prevents that.
zig-snapshots produces before-and-after interactive views of linked executables. Seemingly intended for debugging the zig incremental linker, but seems like it would also be great teaching tool.
A little gem. Seems like it should be possible to combine this with the way hypothesis generates and shrinks inputs. Then you could have a single set of tests that could run exhaustively for small inputs and use coverage-guided fuzzing for large inputs with shrinking to find minimal examples.
Someone at handmade recommended trying gf, yet another gdb frontend. This is one is actually pretty slick, but there are some UX issues that would drive me crazy:
- can't copy-paste from the terminal window or into the file window
- the line-mode view of variables disappears when switching focus to the gdb panel to step forwards
- the watch window doesn't actually create gdb watches (break on read/write), but just evaluates the expression whenever a breakpoint is reached
- whenever gdb asks a question interactively, gf answers 'yes'
By toggling environment.enableDebugInfo to 'true' in /etc/nixos/configuration.nix, all separate debug info derivations in your systemPackages will have their debug output linked in /run/current-system/sw/lib/debug/ and will be automatically available to gdb.
Handles are the better pointers.
A useful glimpse of how an experienced c programmer manages memory.
Duckdb has a blog!