HYTRADBOI
Many new talks have been added to the HYTRADBOI schedule. There are another 15 or so in the pipeline.
It's starting to look pretty exciting.
Milestones
I've been thinking lately about the psychological need for a sense of completion, or at least milestones.
In industrial jobs my work has typically been organized around discrete projects with a clear roadmap like 'support the postgres json api'.
For academics, I imagine papers and conference deadlines produce a similar demarcation of projects and time.
But when doing independent research I've typically fallen into the habit of creating unbounded projects with no internal structure. I don't think this has been good for my sanity.
Ink & Switch have an appealing research model. There's clearly an overarching theme, but the actual research is done in individual three month projects, each of which has a clear goal and finishes with a writeup at the end of the period regardless of what state the project is in.
I think this would kill the sense of sunk costs that keep me moving down a particular branch of research long after the returns have declined.
With that in mind, I've tried to retroactively separate the history of imp into distinct versions. I think both v0 and v1 were well-scoped projects that succesfully answered the motivating questions:
- v0 showed that I could describe a html GUI with relations and get good enough performance to hit frame budgets.
- v1 showed that it is possible to make a relational language that is as capable as sql but with a dramatically simpler specification.
But v2 is a mess that doesn't have a clear goal and is being pulled in many different directions. I wanted to explore using imp as a general-purpose language. I wanted to explore live interaction as a development model. I wanted to explore relational approaches to local-first software. And on top of all of that I was trying to ship something that other people could use.
So I'm going to put a pin in v2. And in the future I think it would be a good idea for each successive effort to have a new version number, a clear focus (especially with regards to research vs development), and a deadline after which I write up the results.
Similarly for dida. If I split the "easier to use and understand" goal into two I think it's fair to say that "easier to understand" is a success. Dida contains all the core ideas of differential dataflow (minus the parallel layer) but is under 2000 lines of direct well-commented code and is accompanied by a detailed explanation of the core algorithms. That's a milestone.
This is a kind of magic trick. I didn't write any new code or give up on any goals, but I no longer feel weighed down by unfinished work.
Data soup
My computer usage is full of tiny CRUD problems that are typically solved either with single-purpose apps or with adhoc manual effort. Here's a random selection off the top of my head:
- reading queue
- currently: whatever is currently downloaded in kindle app, whatever is unread in rss reader, occasionally snoozed emails to self
- problems: list differs between phone and kindle, no solution for non-kindle/rss sources eg academic papers
- bibliography
- current: ratings in goodreads
- problems: goodreads often loses data, doesn't offer search within texts, doesn't work for eg academic papers
- notes
- current: goodreads ratings + kindle annotations + markdown on my website + text files fed into spaced repetition tool
- problems: spread out, multiple formats
- spaced repetition
- current: text files + custom tui + json load/dump of history
- problems: only on laptop, no sync to phone, so rarely used
- work journal
- current: single text file
- problems: no search by date
- todo list
- current: text file on phone, per-day list in work.md, calendar entries, emails left in inbox, notepad on desk
- problems: no sync between different lists on different devices, no support for recurring tasks, no assistance with prioritization or estimating workload
- issue tracking for code/research projects
- current: text file per project
- problems: hard to organize, hard to share
- website
- current: markdown files + git + zola + bash + netlify-cli
- problems: very limited template language leads to doing things manually (eg the 'log' section on the frontpage is edited by hand because zola shortcodes don't have access to global variables) or not at all (eg no anchors for sections on frontpage), non-trivial overhead for creating new posts, workflow for images sucks, incremental build doesn't handle includes in templates correctly (eg have to manually rebuild for every css change because I inline it)
- wife's website
- current: zola + netlify cms
- problems: no drafts, wrong css in previews, editor doesn't support tables
- office hours
- current: calendly + google calendar
- problems: doesn't support fastmail calendar so I have to manually insert busy times in calendly
- shopping list
- current: add items to google sheets throughout week, delete when buying
- problems: mobile ui is clunky, sync uses extravagant bandwidth (seen >50mb for a shopping list with 30 items)
- (don't have signal in the supermarket so any solution has to work offline)
- accounts
- current: mine in julia script using csv statement, wife's in google sheets and entered entirely by hand, total breakdown calculated by hand using outputs from both
- problems: sheets requires far too much manual effort and is error-prone, julia script requires too much technical knowledge
- budget / projections
- current: julia script
- problems: doesn't read from accounts, output is hard to share, my wife can't alter variables
- weight tracker
- current: proprietary android app
- problems: no sync between devices, hard to export data to produce a non-terrible graph
- time tracker
- current: none
- problems: no idea where my time goes
- hytradboi
- current: google forms for talk submissions, hand-edited html for schedule
- problems: no way to track as-yet-unsubmitted talks, annoying to feed data into site generator (eg have to deal with google auth), no support for sending emails (eg send reminder to speakers who haven't uploaded their talk yet)
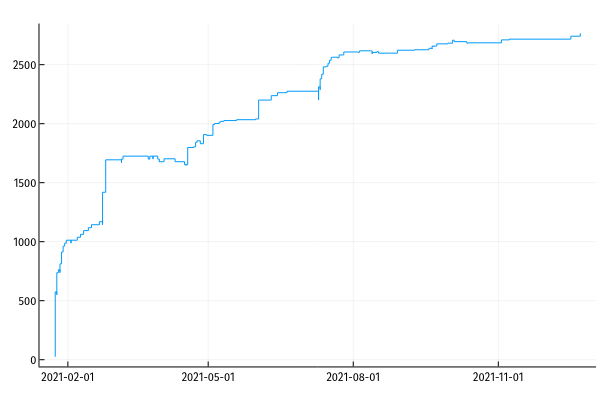
- sponsorship graph (eg)
- current: trigger a csv export from github, download it from my email inbox, run a julia script to produce a graph, click on the graph and save to png, move png to my website repo, add a markdown image link to post
- problems: annoying manual work
- email search
- current: either fastmail ui or notmuch-emacs
- problems: keep forgetting the weird filter dsl, have trouble constructing larger queries
{kind=link}
For most of these the actual logic is not very complicated and the effort lies instead in persistence, cross-device sync, cross-platform gui, automatic deployment etc - the kind of problems I described in Pain we forgot. This is sufficiently effortful that I rarely write code to solve my own problems, even very simple problems like the ones above.
This is why I think a lot of talk about end-user programming misses the point - we don't even have very good solutions for programmer programming yet. There's so much action around different approaches to making it easier to specify the logic, but the logic is the easy part of these problems.
Airtable
Most of the problems above can be solved pretty nicely in airtable.
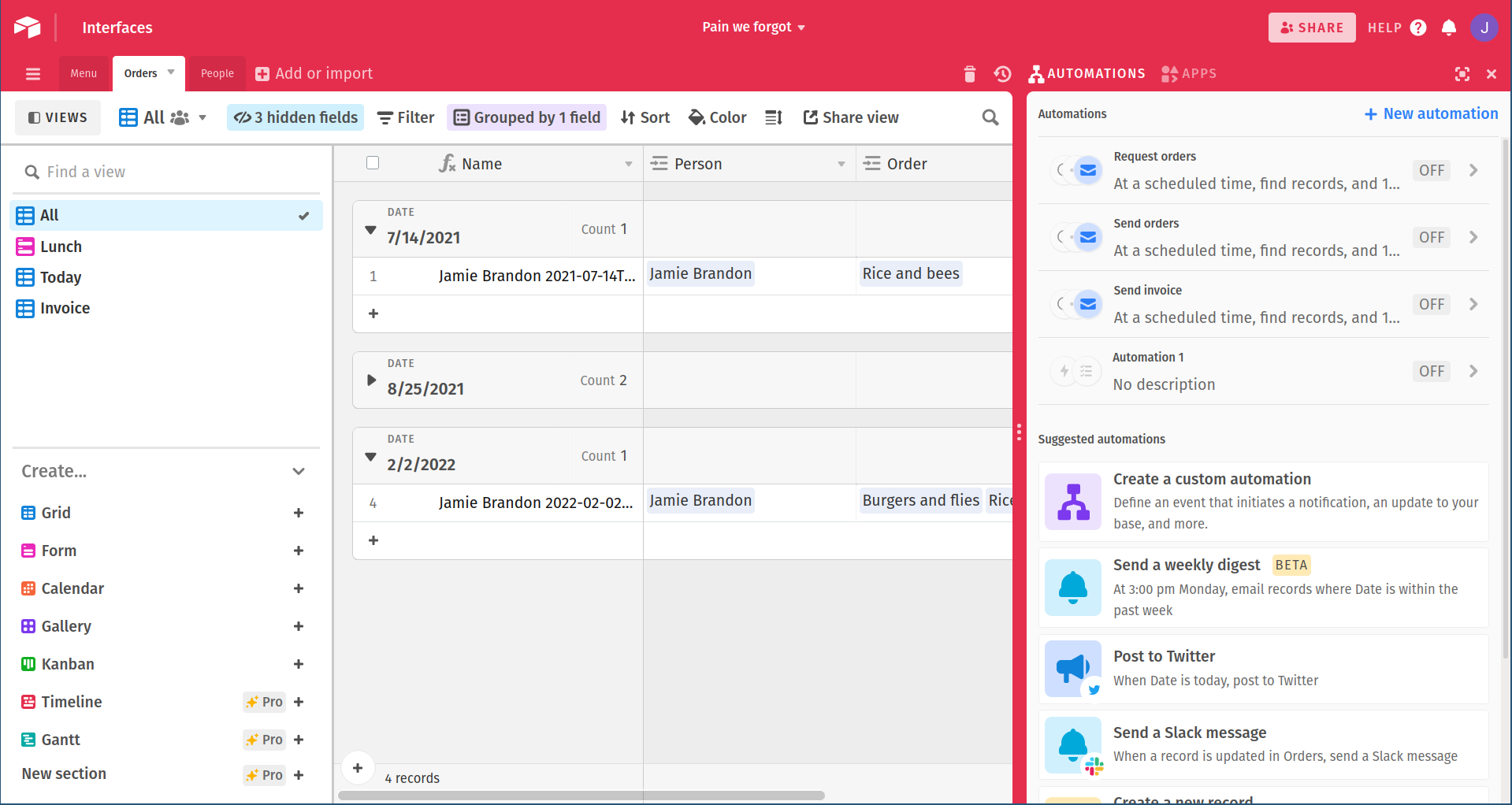
For example, here is the example from Pain we forgot, including automations which send out emails to gather orders from employees and send the days order to the caterer:
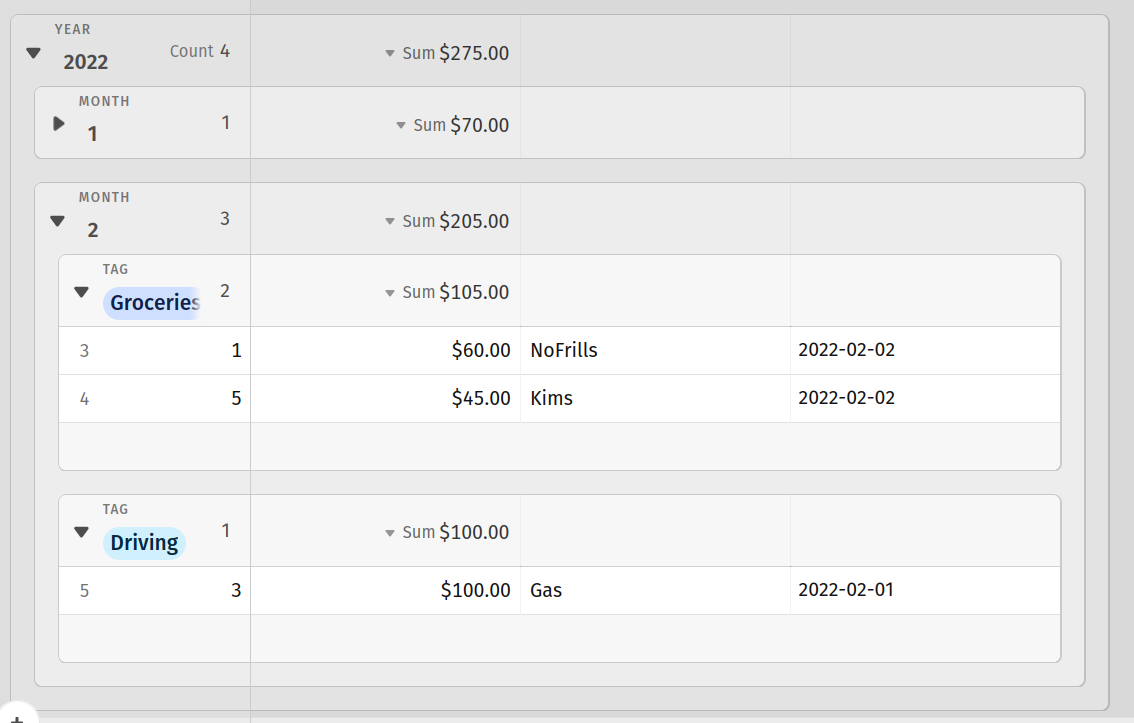
And here is a simple accounts table with total spending broken down by year, month and tag:
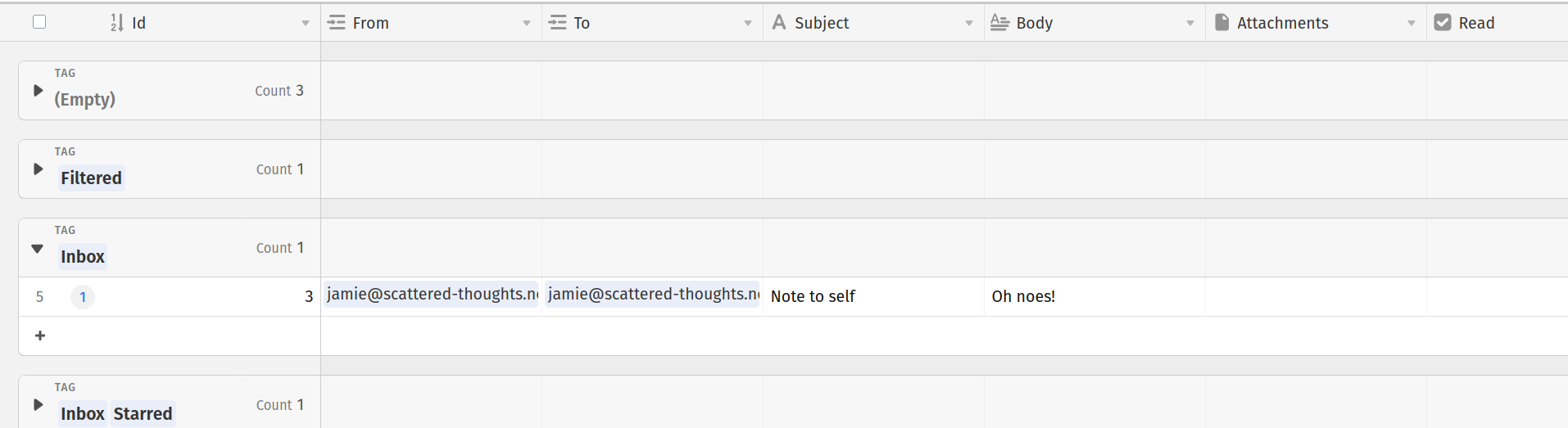
Even my email inbox would look pretty reasonable in airtable:
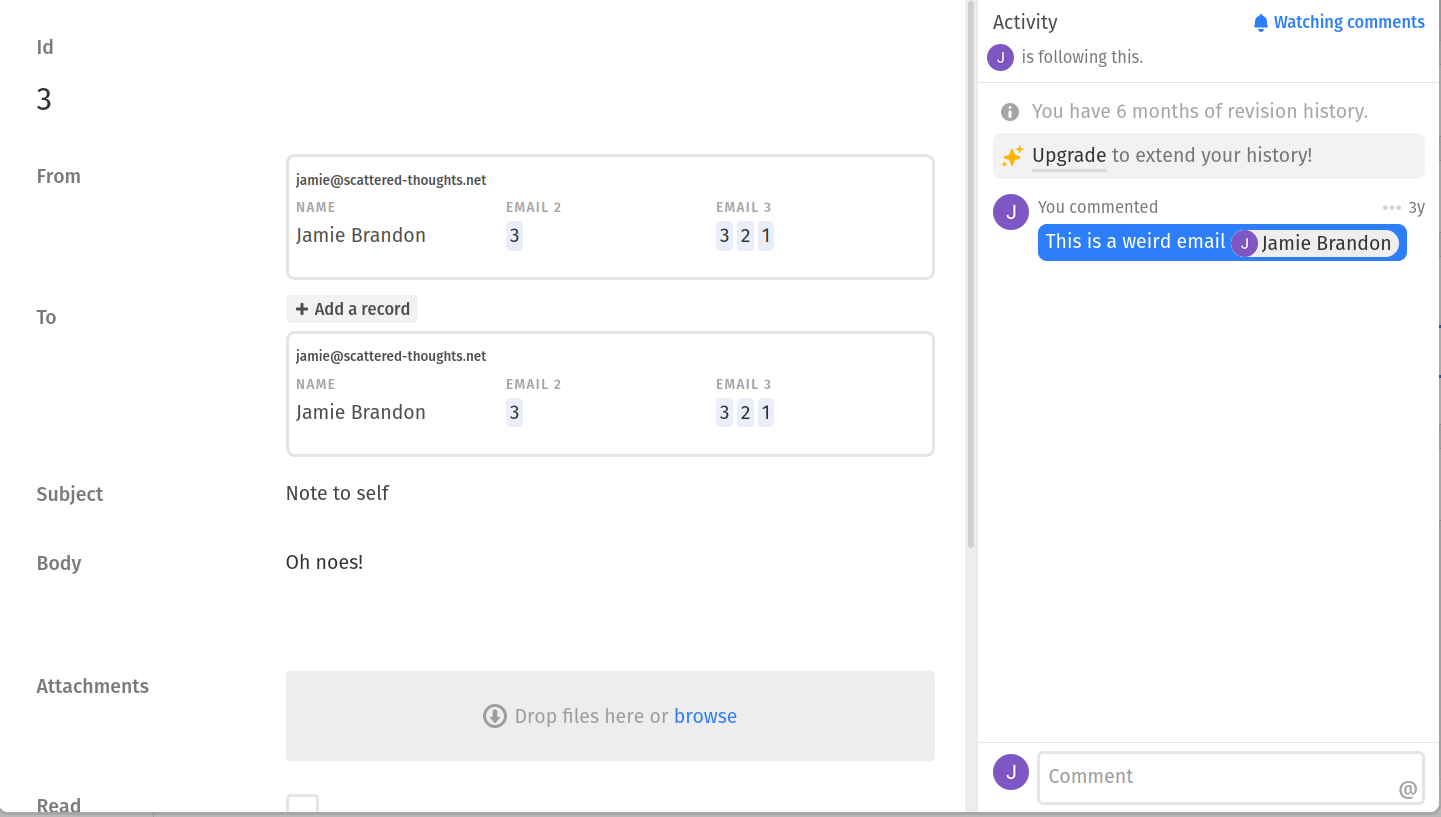
Airtable is not the first software to follow this database + widgets approach but it's by far the best I've used on many axes. For many usecases it's a great solution. Organizations that have complex and constantly changing workflows are typically poorly served by paying for custom software development - misunderstood requirements, frustrating UIs, slow turnaround on change requests. Airtable is a huge improvement.
So why don't I use airtable to solve my data soup problems?
The biggest downside is the existential risk. Airtable has 'over a hundred engineers and over a million lines of code... most of Airtable's engineers are yet to be hired, and most of Airtable's code is yet to be written, by many orders of magnitude'. Airtable seems to be doing very well but the expected lifespan of even very successful SaaS companies is typically much shorter than the lifespan of personal data. That data can be exported from airtable, but the logic and UI can't. Even if the airtable code base was open source it would be far too large to outlive the company - just preventing the build from bitrotting would probably require a full-time maintainer in the long run, given how javascript ecosystems age.
I also get frustrated by arbitrary limitations of the query model. For example if I upload some bank transactions and group by counter-party it will automatically show the total amount spent per counterparty. But if I sort by amount, it sorts the records within each group by amount rather than sorting the groups by total amount. As far as I can tell there is no way to sort the groups. In my existing accounts script there is a list of (regex,tag) pairs. For each transaction, the first matching regex determines the tag. In airtable I'd love for the list of (regex,tag) pairs to itself be a table so it's easy to edit, but it doesn't seem to be possible to do any kind of query across tables except via linked records. The best I've come up with so far is attaching a js script that, when manually triggered, reads from both tables and mutates the tag column. In imp this kind of query is trivial.
The performance would also bug me. The little inbox demo I made takes several seconds to load. The contacts autocomplete popup takes maybe a second, despite the fact that it only has to complete from a list of 3 contacts and they should surely be cached given that I just opened it several times. I have ... 89063 emails in my mailbox. I'm not confident that the UI would take kindly to that. (Loading my mailbox into airtable would also take me into the 'call us' pricing tier.) But with native tools like notmuch-emacs searching in my mailbox typically takes ~50ms.
Finally, I don't like being dependent on an internet connection. Especially for things like todo lists, shopping lists, checking if I have room in my budget for donuts etc which I do from my phone and often in areas with spotty service.
The way I look at it, airtable is this bundle of constraints:
- Solve the 'pain we forgot' problem
- Solve the end-user programming problem
- Maximize ease of use
- Cloud-first
Whereas what I want is:
- Solve the 'pain we forgot' problem
- Expose some expressive query language
- Maximize long-term maintainability
- Local-first
Which opens up all kinds of fun research questions. What would a CRDT look like for an airtable-like schema editor? How could all those myriad UI interactions be handled without mountains of custom UI code? How did Jamie manage to turn a shopping list into a research project?
Fossil
Fossil is the one of the few local-first apps I know that is actually used in anger. It started out as just a DVCS but over time grew a wiki, issue tracker, forum and various other embedded apps. All of which run offline and can be pushed/pulled between repos and even forked.
So I was curious to find out how it worked under the hood.
The underlying data-structure is content-addressed append-only set of artefacts. Forum threads, wiki pages, issues etc are built by summing up the effects of special event artefacts.
Forums are effectively OR-sets - all you can do to a post once it has been made is delete it, leaving a tombstone in the tree.
Wiki pages do last-write-wins. I expected to at least get a merge conflict, but no.
Issues are bags of key-value pairs, where each pair does last-write-wins.
In one sense, it's disappointing that there is so little handling of conflicts.
But on the other hand, there is very little handling of conflicts and it seems like it's fine in practice. So maybe many problems can fall to being broken down into atomic facts and doing last-write-wins for each fact?
Self-hosting
I lurked in various discussions of self-hosting recently. One point that seemed rarely challenged is that self-hosting is hard.
That has been my experience for many pieces of software. But self-hosting fossil is really easy.
What makes most software hard to self-host?
- Too many moving pieces
- Too many configs to learn
- Non-trivial backup and restore
What makes fossil easy to self-host?
- Single executable
- Builtin web server (
fossil serve) - Single file database (easy backup and recovery)
- Sync to other devices (your local working copy of a fossil repo is also a backup)
- Config stored in the database
- Config edited by builtin web interface (
fossil ui)
Other things we could add:
- Automatic updates
- Notifies me first if update requires more than a few seconds downtime, manual action (eg migration) or might break something. (Notifying people is often the part I'm most worried about breaking and is often hard to configure eg synapse wants a separate email gateway set up. But fossil will talk directly to fastmail for me.)
- Self-check
- Notify me if not reachable from the internet
- Notify me if running out of disk space
- Simplified hosting
- Give them a binary and a database, they run it (and restart it if necessary)
- Notify me about crashes/restarts
- Ship a minimal OS that does nothing but run my binary
- Deal with OS upgrades (shouldn't cause problems if not depending on dynamic libraries, userland services etc)
- Put a console/repl in the web interface so I can do bulk edits (eg banning users)
Why isn't this more common? I suspect because most software is optimized for industrial use, not personal use. For industrial uses the operations overhead is not a big deal compared to the development and operational efficiency gained by breaking things up into communicating services. But for personal uses the overwhelming priority is reducing complexity so that nothing fails.
Links
Malloy is a yet another 'better sql', but a pretty credible one. It leans hard into nested relational algebra, producing a language that feels a lot like tableau looks. I was initially put off by the fact that it only supported pre-defined joins, but adhoc joins were added recently.
Andy Matuschak published a 2021 retrospective covering the challenges of creative work, life as an independent researcher, the long-term prospects of patronage and the lack of a 'tools for thought' community.