Things I've been doing in November:
- handmade seattle!
- at tigerbeetle
- hunting performance bugs in the lsm tree
- adding tracing
- evacuating preimp
- musing
- colorblind concurrency
- reading
- fixing my shoulders
Most of the handmade talks aren't up yet. I'll try to remember to link to them next month.
lsm perf
The lsm tree is needed in tigerbeetle to reduce the time taken to recover from crashes and to reduce the cost (ram) of running large databases (vs just having a replicated log on disk and all other state in memory). It's not ready yet though - merging the lsm tree reduced the single node performance on my laptop to ~23k transfers/second (the goal is >1m transfers/second). So that's my main focus at the moment. I've identified a couple of issues so far but haven't fixed any of them yet.
The ssd on my laptop will happily sustain 2gb/s write. During end-to-end benchmarks TB maxes out at ~10mb/s read and 20-80mb/s write and does not appear to be cpu- or memory-bound. So my first suspicion is that we're scheduling io poorly.
Currently every level of every tree is compacted concurrently (actually odd and even levels are compacted in separate phases, but ignore that for now). Each compaction has a pre-allocated fixed-size buffer for reading from and writing to disk. But only insanely large databases ever reach enough lsm levels to make use of all these buffers. In an empty database we only have 1 level per tree, so we're only able to use 1/8th of the buffer space that we're paying for. Under simple benchmarks I'm also seeing that most of the time we're just waiting for the Transfer.id tree to compact - 1 of our 20 trees. So most of the time we're only using 1/160th of our buffer space, leaving us with a maximum of one 64kb read in flight - far too little to maximise disk throughput. This will be solved by doing only a few compactions at once (replacing the 160 small buffers with a few large buffers) and by better pipelining within those few compactions.
We're probably also doing compactions too often. TB currently has very small in-memory tables (use less ram) and large on-disk tables (bigger tables => smaller manifest => less ram). The problem with this is that for compactions from memory to level 0 of the lsm tree:
- The frequency depends on the size of the in-memory table. Smaller table => more frequent compactions.
- THe cost depends on the size of the on-disk tables. Bigger tables => more expensive compactions.
So we're currently in the not-so-sweet-spot of frequent expensive compactions. I tried to estimate the cost of this and it looks like we could cut the compaction write bandwidth by something like 5-8x depending on which solution we go for. (The solution that reduces the compaction bandwidth the most also increases the size of the manifest, which increases checkpoint bandwidth, so it's not a clear win over the next-best option).
Finally, while we're not cpu-bound at the moment, we spend something like 30% cpu on hashing (to detect disk corruption) and 30% on merging tables during compaction. Reducing the number of compactions will help with both of those, but after finishing the current list of optimizations I suspect we'll still end up cpu-bound before hitting 1m transers/second. If so we'll have to either figure out how to optimize one or both of those hotspots or farm them out to a thread pool.
colorblind concurrency
Zig's async/await is implemented as a calling convention rather than as a distinct type. This is intended to prevent the situation in eg rust where async types are contagious and the ecosystem ends up partitioned into sync and async versions of every library. In zig, most library code can just use stdlib io functions and will work correctly (in theory) in both sync and async contexts.
An unfortunate side effect of this is that suspend points are no longer syntactically distinguished. Any function call could potentially suspend, during which some other async function may come in and make arbitary changes to state. This makes it very difficult to reason about code.
For example, if you have a cache that is shared between many tasks then you it's unsafe to hold a pointer to a cached value across a suspend - something else might modify the cache while the current function is suspended. If you don't know where the suspend points are, then to be safe you have to never hold a pointer to a cached value across any function call.
An argument I've seen repeated is that at least this is no worse than writing multi-threaded programs, where any other thread can change your state at any point. I think this is missing the point. Writing correct multi-threaded programs is incredibly hard! The whole appeal of cooperative models like async/await is that you can handle io concurrency without the cognitive overhead of data races and the cpu/cache overhead of scheduling mechanisms like locks and queues.
Perhaps data races are less of a problem if you are writing eg a web app backend, where the entire process is essentially stateless and all actual coordination is offloaded to a separate database server. But zig is a systems language - it seems likely that people will want to write stateful programs! For example, many databases avoid context switches by using a shared-nothing thread-per-core architecture, with a separate async executor per thread (eg ScyllaDB, Redpanda, VoltDB). It would be painful to replicate this architecture in zig at the moment.
In fact tigerbeetle started out by using zig's async/await but ran into too many bugs caused by invisible suspends and had to switch to using explicit callbacks instead. Callbacks have massive downsides of their own - much harder to read, useless stack traces, inability to stack-allocate across suspend points etc. But those downsides are still outweighed by the difficulty of writing correct async/await code without explicit yield points.
The design of async in zig is far from settled, so I've been trying to figure out if there are minimal changes that would allow tigerbeetle to go back to using async/await.
nosuspend blocks are close. They act as a runtime assertion that no function calls within the block will suspend. Perhaps we need a sync block that acts as a comptime assertion that no function calls within the block require an async calling convention. Getting variables out of a block might be syntatically annoying though, especially since zig doesn't have an equivalent yet to rust's statically checked initialization or syntactically-lightweight multiple return from blocks:
// rust: uninitialized variable
let x;
let y;
{
// ...do sync stuff...
x = 1;
y = 2;
}
// error[E0384]: cannot assign twice to immutable variable `x`
x = 2;
// zig: uninitialized variable
var x: usize = undefined;
var y: usize = undefined;
{
// ...do sync stuff...
x = 1;
y = 2;
}
// no compile error
x = 2;
// rust: return from block
let (x,y) = {
// ...do sync stuff...
(1, 2)
};
// zig: return from block
const x_and_y = x_and_y: {
// ...do sync stuff...
break :x_and_y .{1, 2};
};
const x = x_and_y[0];
const y = x_and_y[1];
Another alternative might be a custom lint. At the moment there doesn't seem to be a way at comptime to detect if a function contains a suspend point eg
fn foo() void {
suspend {}
}
pub fn main() void {
// prints .Unspecified instead of .Async
std.debug.print("{}", .{@typeInfo(@TypeOf(foo)).Fn.calling_convention});
}
But if there was a way to detect at comptime whether a function is transitively async, then we could assert that every asynchronous function in our codebase has a name starting with async_ and then it would be easier to spot yield points (especially if I tweak my syntax highlighting to make those names stand out).
Once zig has ide tools that can evaluate comptime code, this could even just be an ide feature rather than a lint, at which point the downsides of colorblind async would be mostly erased.
tracing
Sample-based flamecharts are not very useful for understanding performance issues in tigerbeetle because the callback-based async doesn't preserve stacktraces, and because the main thread is constantly switching between different tasks as io events complete.
Here's a sample-based flamechart from a single-node benchmark:

I can see that it's spending some time in io_uring, in the storage engine and in merging. But I don't know why. Is that one operation or many? What's on the critical path?
Here's the same region with a few manually added traces (~20loc diff):
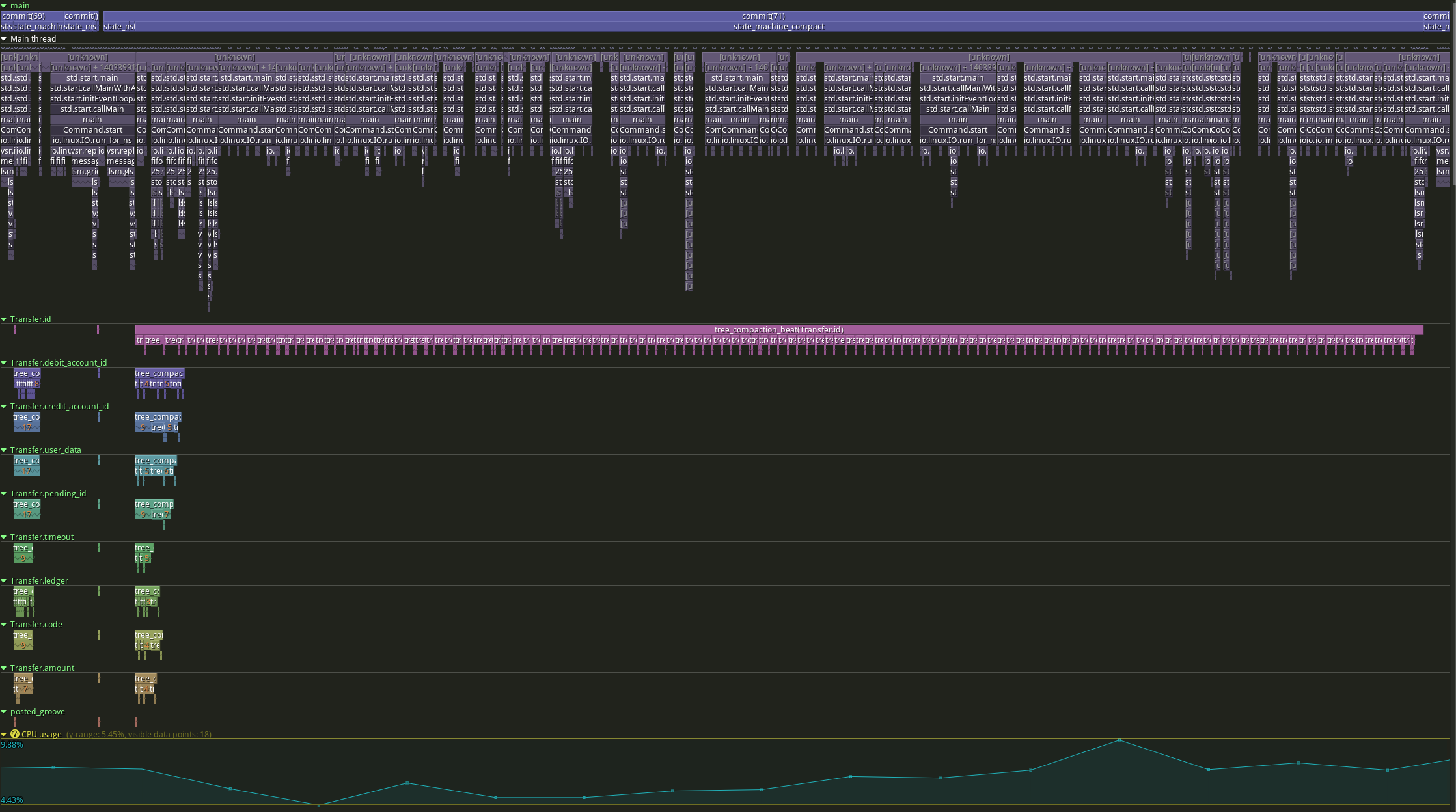
Immediately we can see what is going on - we're in the middle of a long compaction, the Transfer.id tree is still compacting, and all the other trees have finished compacting. The little sawtooths at the bottom of the pink trace show individual merges, so we can see that it's not merge-bound. Once I hook up the io system we'll also be able to see individual reads and writes between the pink merges, at which point it becomes obvious at a glance that the problem is we don't have enough concurrent io.
I thrashed a lot on the api design, eventually realizing that all the tracing systems I'm familiar with are fundamentally designed for systems that are structured differently to tigerbeetle.
Dapper/zipkin/jaeger all have this model where spans have a hierarchy which can be inferred from rpc calls, and spans are grouped into a trace which matches 1:1 with some external rpc call (eg loading a homepage). In tigerbeetle most of the work isn't directly attributable to some external request. Instead there are a number of 'threads' each of which is working on handling some subtask for an entire batch of requests, and then at pre-determined points in the schedule we wait for all the 'threads' to complete their current work (so we can back-pressure the clients instead of letting background work like compaction fall behind).
Most tracing systems also take advantage of either threads or async/await to associate work with a specific context (a thread-local or task-local variable). Tigerbeetle does have a fork/join -like structure to it's concurrency, but it's not expressed in a way that the io scheduler is actually aware of so we can't take advantage of it to manage the span hierarchy.
I ended up resorting to a very manual api where the coder has to specify which logical 'thread' the span belongs to, and is also responsible for ensuring the spans within each logical 'thread' form a tree.
tracer.start(
// Pre-allocated storage for the span start
&tree.tracer_slot,
// The 'thread' name
.{ .tree = .{ .tree_name = tree_name } },
// The event
.{ .tree_compaction_beat = .{ .tree_name = tree_name } },
);
// ...do the work...
tracer.end(
&tree.tracer_slot,
// Specify the 'thread' name and event again to check that we did start/end in the right order.
.{ .tree = .{ .tree_name = tree_name } },
.{ .tree_compaction_beat = .{ .tree_name = tree_name } },
);
Pretty clunky. If we were using async/await it could instead look like:
// The span start is stored on the stack
const span = tracer.start(
// No need to specify 'thread' because we can set it once when spawning the task
.{ .tree_compaction_beat = .{ .tree_name = tree_name } },
);
// No way to get the ordering wrong if we use `defer`
defer span.end();
// ...do the work...
The tracing backend is configured at compile-time. The default is none which simply compiles tracing out entirely.
I added a perfetto backend first because it's really easy to integrate with - just spit out a json file and upload it to ui.perfetto.dev.
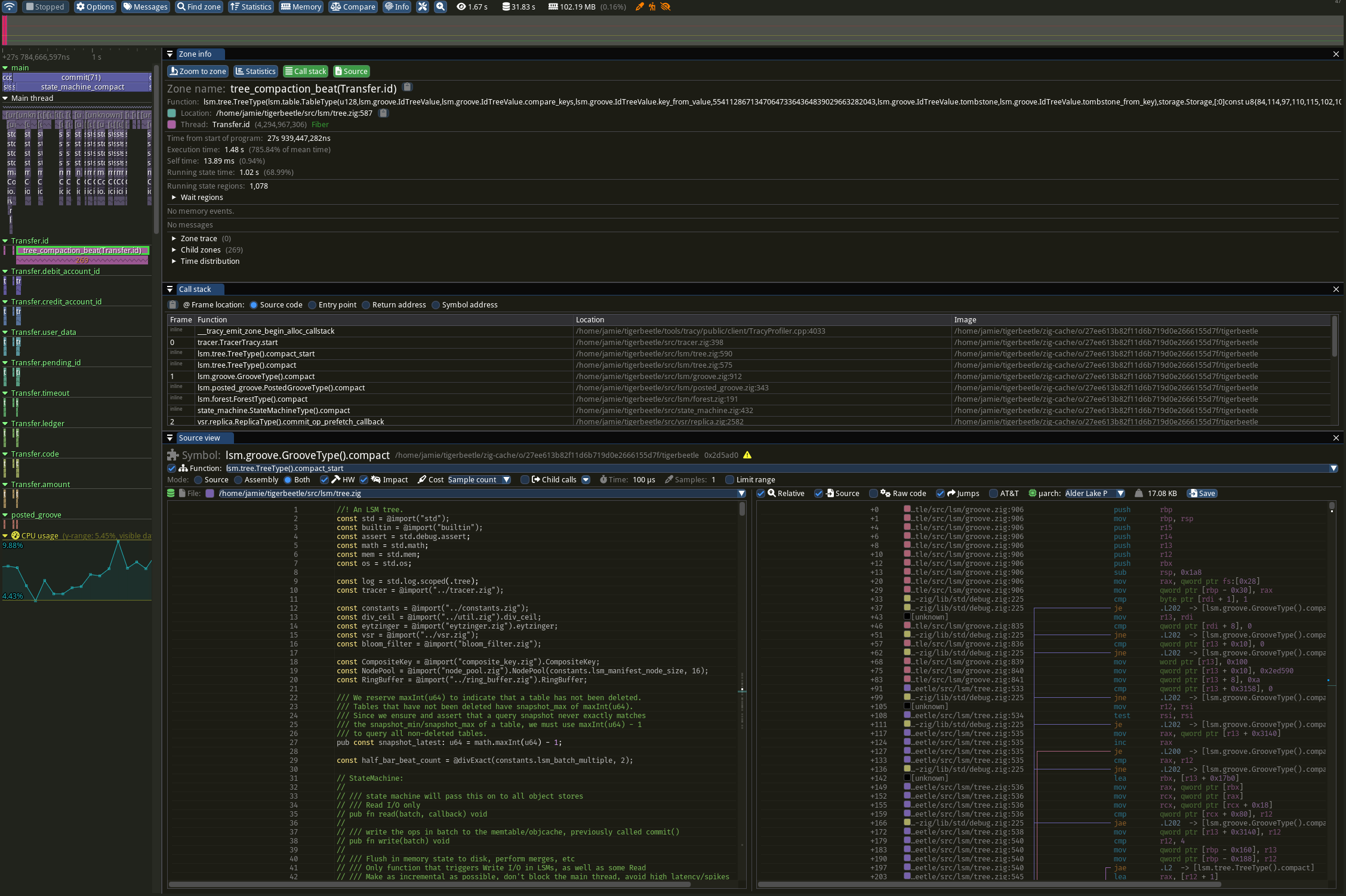
But the main backend is tracy. It's more pain to adopt eg on mac/linux you have to build the ui from source yourself. But it can trace in real-time and also supports sampling, log capture, allocation tracking, perf counters etc all in one timeline. I keep stumbling over new features like the per-span callstacks being linked to the source code view which is annotated with cache miss frequency and linked to the asm view which looks up x86 op latency/throughput...
evacuating preimp
Now that I don't have time to work on preimp - my odd language/database/spreadsheet/thing - I need to port the programs I wrote in preimp to something more that won't bitrot the second I look away.
Most can just be manually-edited scripts, but the few I share with my wife need to be web apps. I couldn't quite bring myself to be entirely pragmatic and port them to javascript, so I wrote them all in zig. Data stored in sqlite. UI almost entirely static html, served by libh2o.
(I tried to use uSockets first since it's used in bun. But many of the capi examples in the repo don't work at all - they crash, return wrong results etc.)
There is near zero documentation for libh2o outside of a few incomplete examples, but I was able to figure it out reasonably easily by just rummaging around in the source code.
I was struck by reading these slides (slideshare, sorry) on the design of h2o and noticing how many of the code examples would be easier in zig - slices instead of null-terminated pointers, loop unrolling (inline for (0..8) |_| do_it() vs repeated macros), comptime sprintf.
libh2o also has a http client but it looks very verbose to use, and it looks like we might get a native zig http client sometime in 2023, so I left all my external service integrations in clojure for now.
But I look forward to never having to maintain any clojure code again. I spent 15 minutes this week debugging this code:
(if (= (get-in wise-transaction ["details" "type"] "CONVERSION"))
; split conversions into two transactions
[{"id" (str "WISE " (get-in wise-transaction ["referenceNumber"]) " SOURCE")
"date" (get-in wise-transaction ["date"])
"amount" (- (get-in wise-transaction ["details" "sourceAmount" "value"]))
"currency" (get-in wise-transaction ["details" "sourceAmount" "currency"])
"description" (get-in wise-transaction ["details" "description"])
"who" user}
{"id" (str "WISE " (get-in wise-transaction ["referenceNumber"]) " TARGET")
"date" (get-in wise-transaction ["date"])
"amount" (get-in wise-transaction ["details" "targetAmount" "value"])
"currency" (get-in wise-transaction ["details" "targetAmount" "currency"])
"description" (get-in wise-transaction ["details" "description"])
"who" user}]
[{"id" (str "WISE " (get-in wise-transaction ["referenceNumber"]))
"date" (get-in wise-transaction ["date"])
"amount" (get-in wise-transaction ["amount" "value"])
"currency" (get-in wise-transaction ["amount" "currency"])
"description" (get-in wise-transaction ["details" "description"])
"who" user}]))
One of those parens is in the wrong place, which results in the if condition always returning true, leading to a null pointer exception in (- (get-in wise-transaction ["details" "sourceAmount" "value"])). This bug wouldn't have been possible in eg javascript, which is saying something.
Similarly for this bug:
(client/post
fetch-url
(merge
fetch-auth
{:headers {:content-type "application/json"
:body (json/write-str fetch-transactions)}}))
The :body should in the outer map. This silently sends the body as a header instead of complaining that no body was given, which manifests as a 40x error because it overflows nginx' header buffer.
It's always really easy and pleasant to write code in clojure, but all the time I gain in writing the code I then lose in laboriously tracking down silly bugs that in a sane language, or even javascript, would have been caught and reported at the source.
Archiving all my back-burnered and abandoned projects felt surprisingly good. It's silly, but having officially declaring them not-in-progress frees up some background threads in my brain.
reading
Understanding software dynamics is on the back-burner for now.
I'm slowly working through database internals. It ignore data models and query engines (things I feel good about) and focuses entirely on storage engines and distributed transactions / consensus (things I feel very shaky on). It doesn't really explain any given topic in enough detail to fully understand, but it works really well as a thorough map of the space - what things you should understand and which papers you should read to understand them.
SplinterDB is a new embeddable database. I watched their talk at cmu but haven't yet dug into the paper. The clear win is borrowing ideas from Beps trees to reduce write amplification. But ~2x less write amplification doesn't exaplain ~8x better throughput and it's not clear to me which of the other differences from existing lsm engines is responsible for the difference. Better concurrency might be the answer, but they don't support transactions yet, which limits the possible use cases. They also haven't implemented logging or checkpointing yet which seems like a big caveat to omit from the benchmarks. Phil Eaton also just pointed me at Mark Callaghan's independent benchmarks which note that splinterdb doesn't fsync.
Four thousand weeks is repetitive but has a few interesting themes. It could have been a really good short book instead of a mediocre long book.
Worry, at its core, is the repetitious experience of a mind attempting to generate a feeling of security about the future, failing, then trying again and again and again...
...develop a taste for having problems. Behind our urge to race through every obstacle or challenge, in an effort to get it "dealt with," there's usually the unspoken fantasy that you might one day finally reach the state of having no problems whatsoever. ...we seem to believe, if only subconsciously, that we shouldn't have problems at all.
How the world really works looks at the full scope of industrial dependence on fossil fuels. In particular, the author is frustrated that environmental debate tends to focus on replacing fossil fuels in electricity production and personal transport, which are both fairly tractable, and ignores that eg we don't know how to produce enough food to stave off famine without using natural gas for synthesizing ammonia. (Kinda prophetic, given the recent spike in food prices.) It doesn't come across as anti- climate action, but rather as a plea to address the entire scope of the problem rather than focusing on the easy parts and declaring the entire problem as solvable.
fixing my shoulders
Over 2022 I had increasingly bad impingement in both shoulders (climbing and coding both encourage a concave posture). Most of the things I was recommended (stretching, massage etc) provided temporary relief but didn't stop the slow constant detoriation.
What did work in the end was a mixture of rotator cuff strengthening (especially external rotation) and PAILS/RAILS stretching (especially internal rotation). I went from unable to complete a single pullup to nearly full function in about 4 weeks.
Weirdly, I seem to be a little stronger now at pulling up and locking off despite having to avoid those movements most of the year. I've read before that scapular and rotator cuff strength can be a limiter on pulling strength, because your nervous system won't let you apply full power if your shoulders are unstable. So maybe that's what's going on.
I'm now trying to get ahead of the next chronic injury by doing regular antagonist training and RAILS/PAILS stretching (replacing static stretching, which doesn't seem to help) for all the troublesome joints, especially wrists, hips and knees. I'm getting too old to only do rehab after injury :S