I gave up on twitter, so this log is now only posted via atom or email.
I wrote a retrospective for 2022.
December things:
- systems distributed
- at tigerbeetle
- random ids?
- deleting tombstones
- disorderly compaction?
- juggling blocks
- code review woes
- holiday shutdown
- musing
- searching for implementors
- everything is copy
- sharing the page cache after fysncgate
- reading
systems distributed
TigerBeetle are organizing a systems conference in cape town in february called Systems Distributed.
I'm most excited for the talk by the antithesis folks - I still have so much to learn about testing.
I would tease more about my own talk, but I haven't written it yet 😬
random ids?
After adding tracing last month, I spent some time just poking around and trying to understand the poor performance that Phil observed here in a very simple example using the go client.
The first thing I noticed was that almost all the latency is due to compaction of the 'transfer.id' secondary index (which maps transfer.id to the internal row id).
![]()
That's weird because in the example code the transfer ids are assigned in ascending order. That means that the transfer.id index should be append-only - a very easy workload for an lsm tree.
I sanity-checked this by setting the transfer code to the same value as the transfer id, so that the transfer.code index should have a similar workload. But the transfer.code compactions were still snappy while the tranfer.id compactions remained slow.
I made the server print out the transactions it was receiving and saw that the id and code fields did not match by the time they reached the server. In fact the id field seemed at first to be totally random, but when I printed out hex instead I saw that their bytes were in the wrong order.
I tried the same example using the zig client and the ids were all correct. So the bug was somewhere in the go client.
The code field is a u16 which is a builtin type in go. But the id field is a u128 which is not a builtin type - it's implemented in the tigerbeetle go code. The code has tests for the roundtrip between hex strings and u128, but both encode and decode use the wrong endianness so the roundtrip tests still pass. I always have a hard time getting endianness right in my head so I added a test where I printed out the byte-for-byte representation for some id in zig and pasted the result into the go tests.
After that the actual fix was simple. #334
deleting tombstones
With the above fix the transfer.id compactions went down to a reasonable level. (It's a little concerning that compacting random ids is so much slower than sequential ids, but I have a long list of improvements to compaction that should address that.)
Now the bottleneck was compacting account.credits_posted and account.debits_posted.
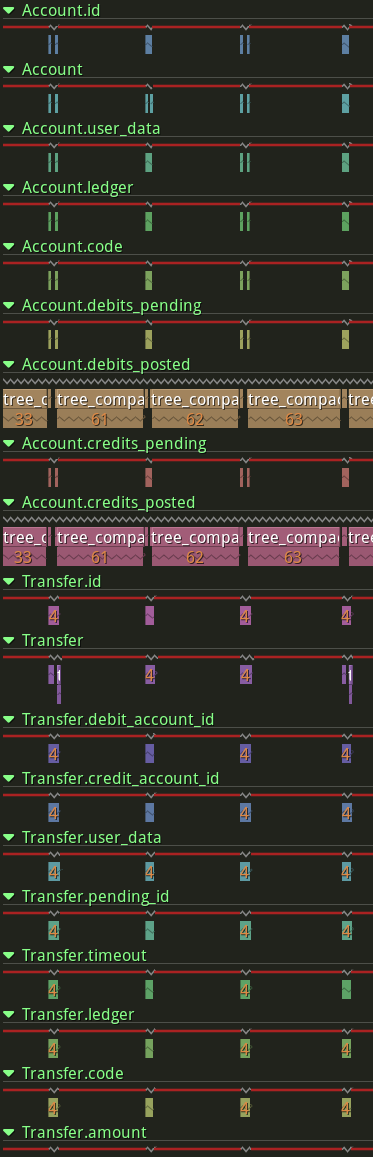
This makes no sense - there are only two accounts in this example workload so the lsm tree should be tiny. Instead, it's filling up the whole of level 0 and starting to compact into level 1.
What on earth is in there? Tombstones. Millions of tombstones, and nothing else.
Quick refresher on how lsm trees work:
- We have a bunch of blocks of sorted key-value pairs (tables).
- These are organized into a hierarchy levels.
- When you want to update the value associated with a key, you just insert a new key-value pair into the top level.
- When a level fills up, we merge some of the tables into the level below (compaction).
- While compacting, if you see two pairs with the same key, you keep the pair that came from the upper level (the most recent entry) and throw away the pair that come from the lower level. (That way old pairs get garbage-collected over time.)
- If you want to delete a key, you insert a special 'tombstone' value into the top level.
- Through compaction the tombstone slowly moves down the tree. When it reaches the bottom level we know for sure that there are no older pairs for the deleted key and we can throw away the tombstone.
In our account.credits_posted index, the key is (credits_posted, row_id) and the value is empty. Whenever the credits_posted field changes for some account, we have to insert (new_credits_posted, row_id) and also insert a tombstone for (old_credits_posted, row_id). We can't drop the tombstone itself until it reaches the bottom of the tree, even though the key it deletes was probably only in the write buffer.
(Now that I think about it, we still shouldn't have been able to accumulate tombstones in level 0 because it is initially the bottom of the tree - the code that drops tombstones might also be wrong...)
Why can't we drop the tombstone as soon as it merges with the entry it's deleting?
Suppose we have the following sequence of events:
put(k,v1)put(k,v2)remove(k)get(k)
The get(k) should return null because the entry for k has been deleted. But if we allowed put(k,v2) and remove(k) to cancel each other out, that would leave put(k,v1) in a lower level and then get(k) would return v1. So we have to keep the tombstone for k around until it reaches the bottom of the tree just in case there are some old puts hanging around.
In our secondary indexes this actually can't ever happen. We never do two puts on the same key without a remove in between. But the lsm code doesn't know that!
So I added a flag in #337 which promises the lsm that we will always alternate put and remove. If this flag is set, it's safe to cancel out tombstones. This tripled throughput for this workload!
Epilogue: DJ discovered a 2020 paper from facebook that mentions a very similar optimization. Rather than a flag in the tree they added a different kind of tombstone called SingleDelete. (I think probably because they have one big lsm tree instead of separate trees for each mysql index, so they have to move the flags into the operations instead.)
disorderly compaction?
In the pr for the tombstones fix I:
- Applied the fix in table_mutable (usually called the 'write buffer' in other lsms).
- Tweaked the tree fuzzer to generate valid workloads for trees with this flag set.
- Applied the fix in compaction too. The existing compaction code used a very general k-way merge iterator which was too complicated to apply this fix to, and also overkill for compactions 2-way merges anyway, so I changed the compaction code to use a specialized iterator instead.
After commit 3 the tree fuzzer found an assert failure in the new compaction code where the keys in the output table weren't written in the correct order. I squinted a bunch at the code I had just written and couldn't see anything obviously wrong.
So I jumped back to the commmit 2 to see what the output should look like. And it crashed again. In the old compaction code.
Now I'm kind of screwed, because commit 2 adds the new fuzzer workload that is used by this crash. So I can't bisect this crash any further back in history.
Instead I made a new branch from there and one-by-one reverted each of the hunks in the diff vs main, eventually arriving at the minimum changes needed to trigger this crash. Most of the changes to the fuzzer and to table_mutable are required, but none of the changes to compaction. I also added an assert that when table_mutable is flushed the output is correctly sorted and this assert never failed.
So we agreed that this must be a pre-existing bug that just needed a very specific workload to trigger, not a new bug in my tombstone pr. I merged my tombstone changes and added the fuzzer crash to the top of my todo list for the next week.
It's lucky I enjoy debugging because this ended up being pretty gnarly. I've tried to recreate the entire process below from my notes, but it took something like 8-10 hours across 3 sessions so inevitably a lot of details are missing.
All I know at the start is:
- I've only found one fuzzer seed that triggers the crash and it happens after a few million operations.
- The first detected symptom is that the output of a compaction merge has two keys with are in the wrong order.
- The crash happened at exactly the same point with both the old compaction code and the new compaction code - so the bug is likely not in compaction itself.
I can't bisect the code history, so the first thing I want to do is bisect the runtime. Where is the first point in time that something went wrong?
The manifest is an in-memory map of the lsm tree. It keeps track of how many tables there are, how big they are, where they are stored on disk and what the min/max key is for each table. If the manifest entries somehow got out of order it would hose everything downsteam. I added asserts before and after each compaction that check that the manifest min/max keys are ordered across each level. No crashes.
For tests/fuzzing we use a mock storage that can be accessed synchronously if needed. So I expanded the manifest asserts to also read from storage and check that the keys in each table are ordered and fall within the min/max keys listed in the manifest. No crashes.
So now I know that at the beginning of compaction the manifest is ordered and correctly describes the data on disk. The bug must happen somewhere after the start of compaction.
Compaction accesses the data via level_iterator and table_iterator. I added asserts to each of these that they yield keys in order. I get a crash in the table_iterator right before the original crash in compaction.
So the keys on disk are in order, but table_iterator is yielding keys out of order.
(If at this point I had printed out all the keys in the table and all the keys yielded by the table_iterator, I could have jumped a few hours ahead. No spoilers though.)
I added one more assert to table_iterator that checked the contents of the table again when the table_iterator started, just in case something had overwriten the data since the start of compaction. No crash.
I've never read the table_iterator code before. Conceptually it's simple, but everything is turned outside out because it has to read from disk using async callbacks. Each block it gets from disk is also only valid for the duration of one callback, so there is some complicated copying and buffering logic too.
I'm immediately suspicious of the edge case that requires sometimes buffering a list of values if the input blocks don't contain enough values to fill an output block. But when I try to step through this in the debugger I find that it's never excercised.
The rest of the logic seems correct, so I'm left with suspicion of the async part. Maybe there is some sort of race, where it issues reads to two data blocks and the second block arrives first? Or maybe it accidentally hangs on to a block past the point where it's invalid?
It's getting late, so I upload a recording to pernosco and go home.
The next day I start poking around in pernosco. I find:
- The crash occurs right after the table_iterator switches to a new block. The last value in the previous block is larger than the first value in the next block.
- The block reads are all serialized - no possibility of races.
So the blocks are correct on disk and they're read in the correct order but then they're wrong in memory.
How do the blocks get from disk to memory? Both the previous and next blocks at the point of the crash were read from the grid cache. So I add an assert to the grid cache that checks at read-time that the cache contents match the disk contents. And it crashes on the previous block! Now we're getting somewhere.
Pernosco has a feature that tracks dataflow to memory regions. So I can click on the cache block and ask for a list of all the points in time where something wrote to that memory. Here's what my pernosco timeline ends up looking like:
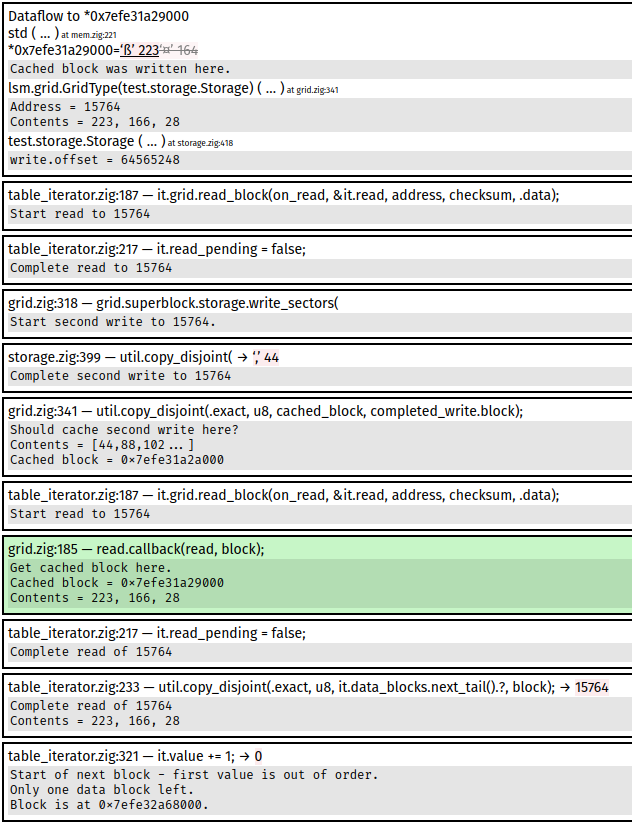
The sequence of events is:
- First write to address 15764.
- The block at 15764 is compacted (so 15764 is no longer referenced by the lsm).
- There is a checkpoint, allowing 15764 to be reused (we have to keep old blocks intact until the next checkpoint in case we crash and have to recover from the last checkpoint).
- Second write to address 15764.
- The block at 15764 is compacted, but compaction reads from the grid cache and sees the first write instead of the second write!
So now I end up reading through the grid cache to understand how it works. It's a k-way clock cache. The exact details don't matter, but the important part is that keys are hashed into buckets, and then within each bucket there is a sort-of-LRU queue. When a key is inserted we first remove any existing entry for that key, and then insert the new entry at the correct point ('way') in the queue (possibly evicting some other key).
Most of the variables in the cache code are optimized out and recording a debug build would take forever, so back to println debugging I go. I print all calls to the cache for address 15764. There's a lot of output so I pipe the results into a file and then use my editor to search around in the file.
Here's what it looks like when it's behaving:
...
Inserting 15764 at way 11
Got 15764 from way 11
Removing 15764 from way 11
Inserting 15764 at way 14
Got 15764 from way 14
...
But just before the crash I see
...
Inserting 15764 at way 14
Got 15764 from way 14
Removing 15764 from way 4
Inserting 15764 at way 5
Got 15764 from way 5
Removing 15764 from way 5
Inserting 15764 at way 15
Got 15764 from way 14
The culprit is Inserting 15764 at way 14 ... Removing 15764 from way 4. It deleted the wrong entry.
The way deletion works in this cache is that there is a 2-bit count for each entry. cache.get only looks at entries with a non-zero count, so in cache.insert when we 'remove' the old entry for a key all we actually have to do is set the count to 0
So I step through this section in rr and confirm that way 4 does have an entry for 15764 and the count is non-zero. So the actual bug happened some time earlier.
I print out the count for way 4 after every cache operation and see this:
...
Inserted 15763 at 1984+6. count(2016 + 4)=0
Inserted 17655 at 2016+4. count(2016 + 4)=1
Got 14941 from 3. count(2016 + 4)=1
Removed 15764 from 2016+4. count(2016 + 4)=0
...
So we insert an entry for address 17655 at way 4, and then just a second later the remove sees an entry for address 15764 at way 4.
The insert function doesn't actually set the value on insert. It just returns a pointer to the value so the caller can set it. Is there anywhere where the caller doesn't set the value immediately?
Sure enough, it's in the grid read path. When we start a read, we need a cache block to read into. (The alternative would be to read into a temporary block and then copy into the cache - doubling the memory bandwidth. Unacceptable!) So we insert the address into the cache to get a pointer to the block which we hand to the io system to eventually read into.
I wasn't around when this code was written, but I imagine the reasoning was like this: Sure, we now have an stale value in the cache. But the grid doesn't allow cache reads for addresses which have a read in flight, so we can't observe this stale value. And the grid doesn't allow evicting cache entries for addresses which have a read in flight, so the entry can't be evicted before the io system writes the correct value.
The problem is subtle. We don't store keys and values separately in the cache- that's usually wasteful eg in the row cache, the key is usually one of the columns of the row. Instead we pass a key_from_value function to the cache. So we don't just have a stale value, we have a stale key too. But we do store a 'tag' - the first 8 bits of the key's hash. So we can only get in trouble if the new key happens to the same tag as the old key.
So here is the bug:
- insert key1 at way1
- write value1 to way1
- insert key1 at way2 (sets count at way1 to 0)
- write value2 to way2
- insert key2 at way1 (sets count at at way1 to 1)
At this point the state is:
- way1: tag(key2) key1 value1 count=1
- way2: tag(key1) key1 value2 count=1
If tag(key1) == tag(key2) then a search for key1 could return value1. That would already explain the bug. What actually happened though was another insert:
- insert key1 at way3 (sets count at way1 to 0)
- write value3 to way3
Now the state is:
- way1: tag(key2) key1 value1 count=0
- way2: tag(key1) key1 value2 count=1
- way3: tag(key1) key1 value3 count=1
The last of insert of key1 incorrectly identified way1 as the existing entry and deleted it, leaving two valid entries for key1. (And also a deleted entry for the still-inflight read to key2). Now depending on the point in time at which we read (ie where the head of the queue is), we can either get key1=value2 or key1=value3. That results in a stale cache read during compaction, producing out-of-order values which then trigger an assertion in the table_builder.
This is a hard bug to trigger! No wonder it was so sensitive to the exact fuzzer workload. If tigerbeetle wasn't deterministic then debugging this would have been hopeless.
In #346 I committed all the asserts I added (to make the fuzzer better at catching similar bugs in the future) along with a really gross hot fix - continue to have stale blocks in the cache but overwrite the blocks address with the new address, so that key_from_value returns the correct key.
juggling blocks
I really wanted to avoid having stale blocks in the cache at all. It took several failed branches before finally getting it right.
What came first was #319 by King. The goal was to improve the grids io scheduling, but it also had a side effect that made my fix much easier. Previously, grid.read_block would grab a cache block before queing the read. After King's changes grid.read_block just queues the read and grabs the cache block later, after the current callback has yielded to the io system. This means that all mutations of the cache happen at the top of the call-stack, so I don't have to worry about whether callbacks could call eg grid.read_block and accidentally evict a block they are currently using. That made my changes much easier to reason about.
The core of the stale block problem is that we want to acquire a cache block when a read starts and then make a cache entry when the read completes. But currently the cache blocks live in the cache and have a 1-1 mapping to cache entries. So we make the cache entry when a read starts and then do some gymastics to prevent ever reading or evicting that entry while the read is still in flight.
So the fix is to just decouple blocks and entries. In #365 the cache now just contains a pointer to a block, rather than the block itself. We allocate enough blocks for each cache entry and for each in-flight read (it's a bounded queue). When a read starts it hands it's own block to the io system. When a read completes, it inserts it's own block into the cache and takes the evicted block instead. This let's us completely remove the entry locking system and simplify the cache interface.
There's a bonus on the write path too. Previously, the writer would pass a block pointer to the grid and when the write completed the grid would copy the contents of the block into a cache block. Now we can avoid that copy by swapping the writer's block with the cache block. This is a little trickier for the caller - they have to be aware that calling write_block will leave them with some other uninitialized block. But halving the memory bandwidth for writes is well worth the complication.
code review woes
I'm spending a lot of time reviewing changes to really intricate code (like bugfixes to log exchange in consensus).
I've started counting all the little ways in which github code review infuriates me.
- Constantly collapses files because it's rendering is too slow to handle 100 line diffs.
- Has no memory of which diffs I expanded, so re-collapses everything on every page load.
- Only allows marking files as read, not individual hunks.
- On making a 1-line change to a file, marks the entire file as unread and doesn't show the diff (I have to manually navigate to the commit)
- Doesn't understand force push, so if you add 1 line to a commit I have to re-review the entire commit.
- Does not allow commenting on lines that weren't changed (eg "You need to also change this function to match your other changes").
- Doesn't allow commenting in the file view, only in the patch view.
- Conversations in the conversation view don't link to the corresponding line in the patch view.
- Conversations do link to the file in the patch view, but on page load big diffs get collapsed which makes the screen scroll to the wrong place.
- Conversations don't update in real time, only when the page is refreshed, resulting in constant comment skew.
I'll trial reviewable after the holidays, but it only fixes some of these complaints.
In my ideal world all of the logic for tracking code review (especially diffs between successive force pushes) would be handled by the vcs itself, exposed in a native library and usable via an editor plugin alongside existing tools like jump-to-definition and type inference.
holiday shutdown
A neat idea from tigerbeetle. Between dec 21 and jan 1 nobody is to log in to slack or push to github. The factory is shutting down for the holidays.
searching for implementors
Tigerbeetle is full of unspecified interfaces like this:
pub fn GridType(comptime Storage: type) type { ... }
This takes a type and returns a type. There are constraints on the input type, but they are specified via comptime assertions rather than via a type. This provides a lot of flexibility at the expense of weaker static enforcement.
But there is another side to this tradeoff that I hadn't thought of before. In eg rust the Storage argument would have to implement some Storage trait and I could ask my ide for a list of all types that implement that trait. In zig, the ide doesn't have that information.
everything is copy
In rust there is a trait called Copy. Types which implement this trait can be implicitly copied eg x = (y, y) is fine if y: Copy, but otherwise you would have to write x = (y.clone(), y.clone()).
In zig everything is implicitly copyable. That means you might accidentally copy a huge struct onto the stack.
I think we might be able to write a lint for this, by dumping the post-analysis ir from the compiler and looking for stack variables above a certain size. But I expect we might also find that a lot of stdlib code for also accidentally copies large values. It's really easy to make this mistake when writing code over generic types that you don't necessarily expect to be instantiated to eg [64 * 1024 * 1024]u8.
I'm not sure if there is a good language-level solution. There is a proposal for pinning but it's maybe the wrong default. And if you did write generic code that accidentally copied a value that might be instantiated to a pinned value, instead of being warned when you wrote the code that you need a Copy bound you would instead only find out when someone called your code with a pinned type.
sharing the page cache after fysncgate
Since fsyncgate I think the consensus is that the only safe option for systems which take correctness seriously is to do direct io and maintain your own page cache. Otherwise even panicking and restarting on fsync failure is not sufficient.
This is fine for a database that is expected to be the main or only process running on the machine, but where does it leave databases that are used for desktop apps (eg firefox uses several sqlite databases)? When using the os page cache all these applications are sharing a single page cache, and that cache uses all free memory on the machine but will shrink the cache if other processes need more memory. If all our desktop apps have to implement their own page cache then there is no way for them to cooperatively decide how much memory to use on caching, or to shrink their caches when other processes need the memory.
Is anyone working on this problem?
reading
Still slowly creeping through database internals.
9 out of 10 climbers make the same mistakes wasn't very useful. Unstructured and rambling.
The rise and fall of peer review.
...knowing that your ideas won't count for anything unless peer reviewers like them makes you worse at thinking. It's like being a teenager again: before you do anything, you ask yourself, 'BUT WILL PEOPLE THINK I'M COOL?'
In some ways it makes sense that peer review is poor. Just think how hard it is to do code review properly (as opposed to just skimming the changes and seeing if they look plausible), and that's with the added motivation of knowing that any bugs you miss now you'll find yourself debugging later.
There is a perception that microprocessor architects have - out of malice, cowardice, or despair - inflicted concurrency on software. In reality, the opposite is the case: it was the maturity of concurrent software that led architects to consider concurrency on the die. (The reader is referred to one of the earliest chip multiprocessors - DEC's Piranha - for a detailed discussion of this motivation.) Were software not ready, these microprocessors would not be commercially viable today. If anything, the 'free lunch' that some decry as being over is in fact, at long last, being served. One need only be hungry and know how to eat!