Gel (née edgedb) paid me to write a review of their query language, edgeql. I agreed on the basis that I'd write whatever I honestly thought and they could decide whether wanted to publish it or keep it to themselves.
Direct quotes from the gel team are marked as quotes.
Like this.
Everything else is my own opinion and my own mistakes.
This is a long post. The first half is just an argument that things-like-gel are needed. If you are already on board, you might want to skip to the second half which is a detailed critique of edgeql.
the structure has to happen somewhere
Here are two pages from the internet movie database.
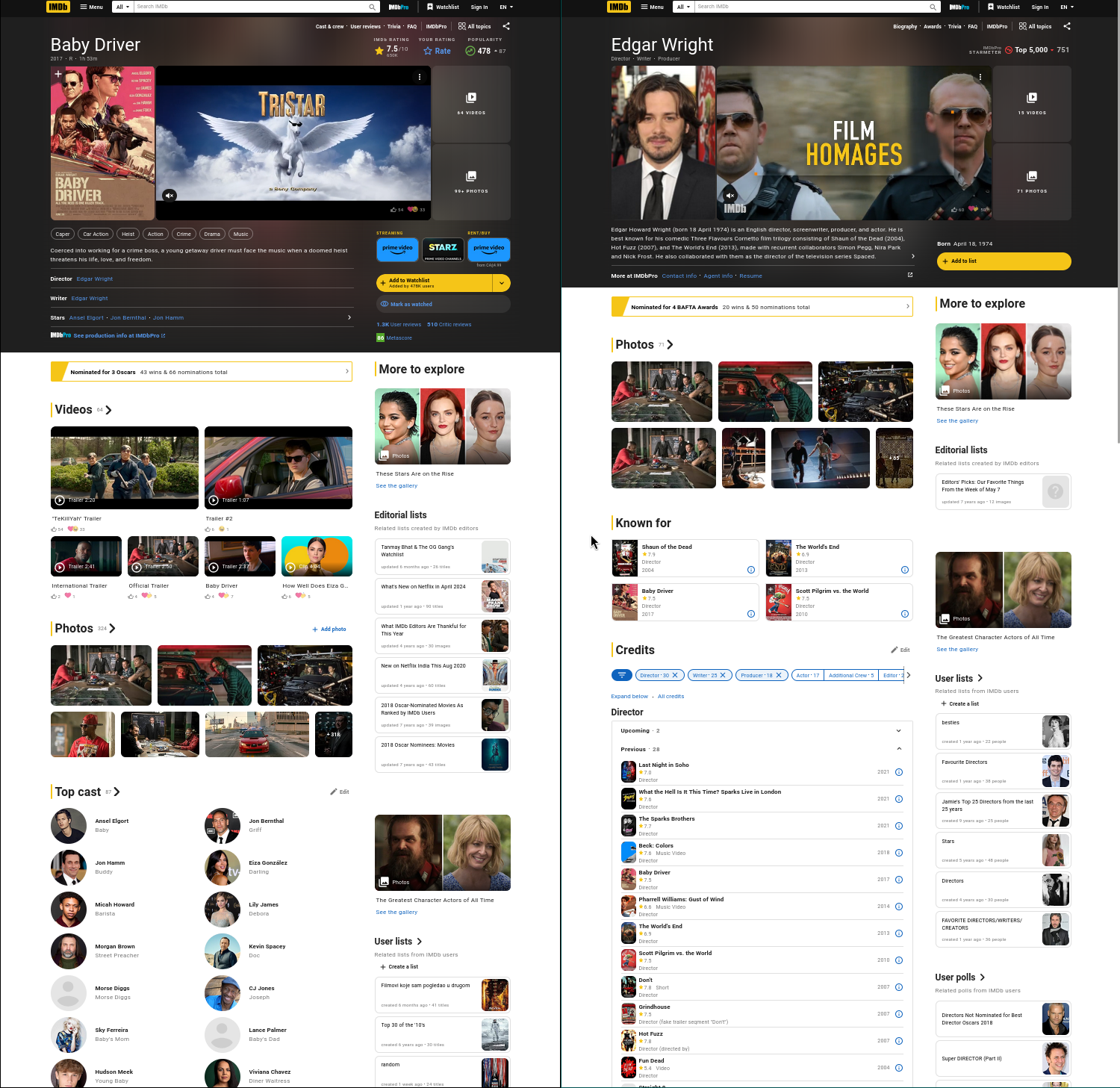
There are two things to note about these pages.
-
The data on the page is presented in a hierarchichal structure. The movie page contains a director, a list of genres, a list of actors, and each actor in the list contains a list of characters they played in the movie. You can't sensibly fit all of this into a single flat structure like a relation.
-
The order of the hierarchy isn't the same on both pages. On one page we have movie->actors and on the other page we have actor->movies. So you can't just directly store the hierarchy in your database - you need to be able to traverse relationships in both directions.
So we store all our data in a relational database in flat tables and then whenever we need to render some UI we transform the flat data into whatever hierarchy we need. Doing this by hand is tedious and error-prone.
We call this "the object-relational mismatch" but it isn't really about objects or relations. The fundamental problem is that fitting complex relationships to human vision usually requires constructing some visual hierarchy, but different tasks require different hierarchies.
Whatever database and programming language you use, you will have to deal with this. But it's particularly painful in sql because sql wasn't designed to produce hierarchical data.
sql wasn't built for structure
Let's grab the imdb public dataset and try to reproduce the source data for that movie page (or at least a subset of it, because I didn't bother importing all the tables). We want to see an output that looks like this:
{
"title": "Baby Driver",
"director": ["Edgar Wright"],
"writer": ["Edgar Wright"]
"genres": ["Action", "Crime", "Drama"],
"actors": [
{"name": "Ansel Elgort", "characters": ["Baby"]},
{"name": "Jon Bernthal", "characters": ["Griff"]},
{"name": "Jon Hamm", "characters": ["Buddy"]},
{"name": "Eiza González", "characters": ["Darling"]},
{"name": "Micah Howard", "characters": ["Barista"]},
{"name": "Lily James", "characters": ["Debora"]},
{"name": "Morgan Brown", "characters": ["Street Preacher"]},
{"name": "Kevin Spacey", "characters": ["Doc"]},
{"name": "Morse Diggs", "characters": ["Morse Diggs"]},
{"name": "CJ Jones", "characters": ["Joseph"]}
],
}
Let's grab the title first:
postgres=# select primaryTitle from title where tconst = 'tt3890160';
primarytitle
--------------
Baby Driver
And now we need the director:
postgres=# select primaryTitle, person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'director';
primarytitle | primaryname
--------------+--------------
Baby Driver | Edgar Wright
And the writer:
postgres=# select
primaryTitle,
director.primaryName as director,
writer.primaryName as writer
from title,
principal as principal_director, person as director,
principal as principal_writer, person as writer
where title.tconst = 'tt3890160'
and title.tconst = principal_director.tconst
and principal_director.nconst = director.nconst
and principal_director.category = 'director'
and title.tconst = principal_writer.tconst
and principal_writer.nconst = writer.nconst
and principal_writer.category = 'writer';
primarytitle | director | writer
--------------+--------------+--------------
Baby Driver | Edgar Wright | Edgar Wright
We're already in trouble. If this movie had 2 directors and 2 writers, this query would return 4 rows. If there was no director in the database then this query would return 0 rows, no matter how many writers there were.
We can't fit the data we want into a single relation, and we can't return more than one relation per query. So we have to issue multiple queries:
postgres=# select primaryTitle from title where tconst = 'tt3890160';
primarytitle
--------------
Baby Driver
postgres=# select person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'director';
primaryname
--------------
Edgar Wright
postgres=# select person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'writer';
primaryname
--------------
Edgar Wright
postgres=# select person.nconst, person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'actor'
limit 10;
nconst | primaryname
-----------+---------------
nm5052065 | Ansel Elgort
nm1256532 | Jon Bernthal
nm0358316 | Jon Hamm
nm2555462 | Eiza González
nm8328714 | Micah Howard
nm4141252 | Lily James
nm3231814 | Morgan Brown
nm0000228 | Kevin Spacey
nm1065096 | Morse Diggs
nm1471085 | CJ Jones
postgres=# select principal_character.nconst, principal_character.character
from title, principal, principal_character
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'actor'
and principal_character.tconst = principal.tconst
and principal_character.nconst = principal.nconst;
nconst | character
-----------+---------------------
nm5052065 | Baby
nm8328714 | Barista
nm0358316 | Buddy
nm2555462 | Darling
nm4141252 | Debora
nm0000228 | Doc
nm1256532 | Griff
nm1471085 | Joseph
nm1065096 | Morse Diggs
nm3231814 | Street Preacher
Through the magic of joins we have retrieved all the data we need and it only required holding a transaction open for 4 network roundtrips.
All that's left to do now is... the same joins, but in the backend server. Because we have to re-assemble these flat outputs into the structure of the page.
Also note that half of the data returned is nconst which we didn't even want in the output. We only returned it because we need it as a key so we can repeat the joins that we already did.
All of this is pretty tedious so we invented ORMs to automate it. But:
- Almost all ORMs end up sending multiple queries for the output that we want. If you have a good ORM and you use it carefully it'll send one query per path in the output, like the raw sql above. If you're less careful you might get one query per actor in the film.
- Many ORMs also make a mess of consistency by lazily loading data in separate transactions. So we might generate a page where different parts of the data come from different points in time.
- Using an ORM locks you into only using one specific programming language. What if you need to query your data from a different language? You'll probably end up talking to the same ORM through a microservice.
old dogs can halfway learn new tricks
These days sql actually can produce structured data from queries.
A lot of people are mad about this. Whenever I talk about it they reflexively yell things like "structured data doesn't belong in the database" as if there was a universal system of morality that uniquely determined the locations of various data processing tasks.
But I can't help but notice again that the structure has to happen somewhere because that's what the output page looks like and that doing it outside the database isn't working very well.
Whenever we're building a UI for humans, whether on the web or native, the main use of the query language is to turn relational data into structured data for the client to render. So it would be really nice if the query language was able to produce structured data rather than making us do a bunch of redundant work in the backend.
Like this:
select jsonb_agg(result) from (
select
primaryTitle as title,
genres,
(
select jsonb_agg(actor) from (
select
(select primaryName from person where person.nconst = principal.nconst) as name,
(
select jsonb_agg(character)
from principal_character
where principal_character.tconst = principal.tconst
and principal_character.nconst = principal.nconst
) as characters
from principal
where principal.tconst = title.tconst
and category = 'actor'
order by ordering
limit 10
) as actor
) as actors,
(
select jsonb_agg(primaryName)
from principal, person
where principal.tconst = title.tconst
and person.nconst = principal.nconst
and category = 'director'
) as director,
(
select jsonb_agg(primaryName)
from principal, person
where principal.tconst = title.tconst
and person.nconst = principal.nconst
and category = 'writer'
) as writer
from title
where tconst = $1
) as result;
It's not perfect. You can definitely see the duct tape. But we can grab all the data needed for the entire page in a single query, with one network roundtrip, and no post-processing - the backend can pass that json directly to the client.
So what if we designed a query language specifically for producing structured data and then compiled it to the above sql? Here is the same query in edgeql:
select Title{
title := .primaryTitle,
genres,
actors := (
select .<title[is Principal]{
name := .person.primaryName,
characters := .characters,
}
filter .category = "actor"
order by .ordering
limit 10
),
director := (
select .<title[is Principal]
filter .category = "director"
).person.primaryName,
writer := (
select .<title[is Principal]
filter .category = "writer"
).person.primaryName,
}
filter .tconst = <str>$tconst
The actual generated sql is crufty, but once the query planner strips away the boilerplate it ends up with pretty much the same query plan:
─────────────────────── Fine-grained Query Plan ───────────────────────
│ Time Cost Loops Rows Width │ Plan Info
┬── │ 0.4 5443.69 1.0 1.0 32 │ ➊ IndexScan relation_name=Title,
│ │ │ scan_direction=Forward,
│ │ │ index_name=constraint 'std::exclus
│ │ │ ive' of property 'tconst' of objec
│ │ │ t type 'default::Title'
├── │ 0.0 28.53 1.0 1.0 32 │ ➊ Aggregate strategy=Plain,
│ │ │ partial_mode=Simple
│ │ 0.0 28.51 1.0 3.0 7 │ IndexScan
│ │ │ relation_name=Title.genres,
│ │ │ scan_direction=Forward,
│ │ │ index_name=Title.genres_idx0
├┬─ │ 0.3 1678.1 1.0 1.0 32 │ ➋ Aggregate strategy=Plain,
││ │ │ partial_mode=Simple
││ │ 0.2 1677.97 1.0 8.0 48 │ Limit
││ │ 0.2 3105.35 1.0 8.0 48 │ SubqueryScan
│╰┬ │ 0.2 3104.43 1.0 8.0 50 │ Result
│ ├ │ 0.0 1523.41 1.0 8.0 50 │ ➋ Sort sort_method=quicksort,
│ │ │ │ sort_space_used=25kB,
│ │ │ │ sort_space_type=Memory
│ │ │ 0.0 1520.18 1.0 8.0 50 │ Result
│ │ │ 0.0 1520.18 1.0 8.0 34 │ IndexScan relation_name=Principal,
│ │ │ │ scan_direction=Forward,
│ │ │ │ index_name=Principal.title index
│ ├ │ 0.1 8.58 8.0 1.0 14 │ ➌ IndexScan relation_name=Person,
│ │ │ │ scan_direction=Forward,
│ │ │ │ index_name=constraint 'std::exclus
│ │ │ │ ive' of property 'id' of object ty
│ │ │ │ pe 'default::Person'
│ ╰ │ 0.1 8.6 8.0 1.0 32 │ ➍ Aggregate strategy=Plain,
│ │ │ partial_mode=Simple
│ │ 0.1 8.58 8.0 1.0 12 │ IndexScan
│ │ │ relation_name=Principal.characters
│ │ │ ,
│ │ │ scan_direction=Forward,
│ │ │ index_name=Principal.characters_id
│ │ │ x0
├┬─ │ 0.0 1804.08 1.0 1.0 32 │ Aggregate strategy=Plain,
││ │ │ partial_mode=Simple
││ │ 0.0 1803.99 1.0 1.0 14 │ Result
││ │ 0.0 1803.99 1.0 1.0 14 │ NestedLoop join_type=Inner
│├─ │ 0.0 1520.6 1.0 1.0 16 │ ➏ Aggregate strategy=Hashed,
││ │ │ partial_mode=Simple
││ │ 0.0 1520.18 1.0 1.0 16 │ IndexScan relation_name=Principal,
││ │ │ scan_direction=Forward,
││ │ │ index_name=Principal.title index
│╰─ │ 0.0 8.58 1.0 1.0 30 │ ➎ IndexScan relation_name=Person,
│ │ │ scan_direction=Forward,
│ │ │ index_name=constraint 'std::exclus
│ │ │ ive' of property 'id' of object ty
│ │ │ pe 'default::Person'
╰┬─ │ 0.0 1924.52 1.0 1.0 32 │ Aggregate strategy=Plain,
│ │ │ partial_mode=Simple
│ │ 0.0 1924.39 1.0 1.0 14 │ Result
│ │ 0.0 1924.39 1.0 1.0 14 │ NestedLoop join_type=Inner
├─ │ 0.0 1520.77 1.0 1.0 16 │ ➑ Aggregate strategy=Hashed,
│ │ │ partial_mode=Simple
│ │ 0.0 1520.18 1.0 1.0 16 │ IndexScan relation_name=Principal,
│ │ │ scan_direction=Forward,
│ │ │ index_name=Principal.title index
╰─ │ 0.0 8.58 1.0 1.0 30 │ ➐ IndexScan relation_name=Person,
│ │ scan_direction=Forward,
│ │ index_name=constraint 'std::exclus
│ │ ive' of property 'id' of object ty
│ │ pe 'default::Person'
The edgeql version has some clear advantages:
- The syntax was designed for structured data, whereas in sql structure was tacked on very recently. The only way in sql to nest relations is to convert them into arrays, but we can't even do that directly because relations are not really first-class values, so we have to do this
( select jsonb_agg(actor) from ( ... ) as actor ) as actorsdance. Whereas in edgeql we can just writeactors := ( ... ). - Edgeql has syntactic sugar for the overwhelmingly common case of following foreign keys in either direction. In sql we write
( select primaryName from person where person.nconst = principal.nconst ) as namebut in edgeql we can just writename := .person.primaryName.
This is just a toy query so the difference isn't overwhelming. But look at the amount of nesting on the imdb movie page - I stopped counting at 50 subqueries. Writing that query by hand in sql would be unpleasant.
Gel is built on top of postgres, so the basic pitch is to keep all the machinery of postgres, but update the interface to match the kinds of problems and workflows that we're faced with today.
I'm roughly on board with that plan, having complained at length about the problems with sql. But the devil is in the details, so let's get into those.
schema
Here is the schema I used for the imdb data:
type Person {
required nconst: str {
constraint exclusive;
};
required primaryName: str;
optional birthYear: int16;
optional deathYear: int16;
multi primaryProfession: str;
multi knownForTitles: str;
}
type Title {
required tconst: str {
constraint exclusive;
};
required titleType: str;
required primaryTitle: str;
required originalTitle: str;
required isAdult: bool;
optional startYear: int16;
optional endYear: int16;
optional runtimeMinutes: int32;
multi genres: str;
}
type Principal {
required person: Person;
required title: Title;
required ordering: int16;
required category: str;
optional job: str;
multi characters: str;
}
It's not that different from sql. Each of these types is effectively a table. Each gets an auto-uuid field.
A field like nconst: str is just a string column. A field like person: Person is a foreign key to the Person auto-uuid column.
Writing required is equivalent to declaring a column not nullable.
A multi field generates a separate postgres table under the hood to record a one-to-many relationship.
main=# \d "Person.primaryProfession"
Table "public.Person.primaryProfession"
Column | Type | Collation | Nullable | Default
--------+------+-----------+----------+---------
source | uuid | | not null |
target | text | | not null |
None of this feels very different from the way you would model the same data in postgres. It's just adding some sugar for common patterns.
declarative schema
The big difference from sql is that you don't write DDL statements yourself.
When working on the imdb data, I ran gel watch --migrate in the background so that whenever I changed the schema file it migrated my dev database to match. When I was ready to check code in I ran gel migration create to create a migration file that could be applied in production:
> gel migration create
did you create constraint 'std::exclusive' of property 'nconst'? [y,n,l,c,b,s,q,?]
> ?
y or yes - Confirm the prompt ("l" to see suggested statements)
n or no - Reject the prompt; server will attempt to generate another suggestion
l or list - List proposed DDL statements for the current prompt
c or confirmed - List already confirmed EdgeQL statements for the current migration
b or back - Go back a step by reverting latest accepted statements
s or stop - Stop and finalize migration with only current accepted changes
q or quit - Quit without saving changes
h or ? - print help
did you create constraint 'std::exclusive' of property 'nconst'? [y,n,l,c,b,s,q,?]
> y
did you rename object type 'default::Principle' to 'default::Principal'? [y,n,l,c,b,s,q,?]
> y
did you alter object type 'default::Title'? [y,n,l,c,b,s,q,?]
> y
Created dbschema/migrations/00002-m12amdb.edgeql, id: m12amdbpsuxembcum4tytusmf2sxvr62ba45z6gozzvnsjpbbm7ytq
> cat dbschema/migrations/00002-m12amdb.edgeql
CREATE MIGRATION m12amdbpsuxembcum4tytusmf2sxvr62ba45z6gozzvnsjpbbm7ytq
ONTO m1rbqggtqctdexgvnyxrshh4icmz3wz2ai5yynve4y6kinynkyus4a
{
ALTER TYPE default::Person {
ALTER PROPERTY nconst {
CREATE CONSTRAINT std::exclusive;
};
};
ALTER TYPE default::Principle RENAME TO default::Principal;
ALTER TYPE default::Title {
ALTER PROPERTY runtimeMinutes {
SET OPTIONAL;
SET TYPE std::int32;
};
ALTER PROPERTY startYear {
SET OPTIONAL;
};
ALTER PROPERTY tconst {
CREATE CONSTRAINT std::exclusive;
};
};
};
This is a much nicer workflow than tweaking the database by hand during development and trying to remember to track the same changes in a migration file by hand.
The migrations contain a hash, and the hash of their parent migration, and will refuse to be applied to a database whose schema doesn't match the parent hash. If you want to edit the migration, gel migration edit will recalculate the hash for you.
Like with the schema, this is all what you would do normally in postgres, but having these common patterns backed into the language and tooling makes life easier.
object subtypes
When selecting an object we can define extra fields:
gel_toy:main> select Person{primaryName := "Replaced!", nonsense := 42} limit 1;
{default::Person {primaryName: 'Replaced!', nonsense: 42}}
What is the type of this object? It's not Person because Person doesn't have a nonsense field. It must be some subtype of person.
If it's a subtype then we would expect it to be usable wherever a Person is usable, which means that we can't change the types of the existing fields.
gel_toy:main> select Person{primaryName := 42};
error: SchemaError: cannot redefine property 'primaryName' of object type 'default::Person' as scalar type 'std::int64'
┌─ <query>:1:30
│
1 │ select Person{primaryName := 42};
│ ^^ error
│
= property 'primaryName' of object type 'default::Person' is defined as scalar type 'std::str'
But can we change the types of the extra fields?
gel_toy:main> with peeps := (select Person{nonsense := 42} limit 1) select peeps{nonsense := "?"};
error: SchemaError: cannot redefine property 'nonsense' of object type 'default::Person' as scalar type 'std::str'
┌─ <query>:1:80
│
1 │ with peeps := (select Person{nonsense := 42} limit 1) select peeps{nonsense := "?"};
│ ^^^ error
│
= property 'nonsense' of object type 'default::Person' is defined as scalar type 'std::int64'
Nope. I can't think of a reason why that restriction is necessary, but maybe it was just easier to implement it that way and it never comes up in practice.
So are the extra fields typed nominally or structurally?
gel_toy:main> with
a := (select Person{primaryName := "Replaced!"} limit 1),
b := (select Person{primaryName := "Replaced!"} limit 1)
select {a,b};
error: SchemaError: cannot create union (default::Person | default::Person) with property 'primaryName' it is illegal to create a type union that causes a computed property 'primaryName' to mix with other versions of the same property 'primaryName'
┌─ <query>:4:8
│
4 │ select {a,b};
│ ^^^^^ error
Looks like each expression is effectively generating a new nominal type. I assume the reason for this is that in the generated sql they want to be able to just track the object id and evaluate the fields lazily when needed. If they allowed mixing sources then it would be tricky to keep track of what expression to evaluate.
We'd like to support that eventually, but it is tricky to keep track of the expressions. The plan for how we might do it involves actually computing the expressions in the different branches.
We can also create anonymous objects, and it looks like these are just subtypes of Object with extra fields.
gel_toy:main> select {field := 42};
{Object {field: 42}}
gel_toy:main> with a := {field := 42}, b := {field := 42} select {a,b};
error: SchemaError: cannot create union (std::FreeObject | std::FreeObject) with property 'field' it is illegal to create a type union that causes a computed property 'field' to mix with other versions of the same property 'field'
┌─ <query>:1:52
│
1 │ with a := {field := 42}, b := {field := 42} select {a,b};
│ ^^^^^ error
So we can only mix values from different expressions if none of their fields have been overridden. And we also can't override the id field of an object:
gel_toy:main> select Person{id := <uuid>"new"} limit 1;
error: QueryError: cannot assign to property 'id'
┌─ <query>:1:15
│
1 │ select Person{id := <uuid>"new"} limit 1;
│ ^^^^^^^^^^^^^^^^^ error
This effectively means that you can't use objects for transient values, but only for values which exist in the database. An object is not so much a value as a pointer to a row in a table.
This is not the case in sql - since ROW types were added it's been possible to talk about rows without having to insert them into a table first.
value types
One of the problems with the sql standard is that it doesn't have a way to coin new types of values. In a regular programming language you could make eg a DateTimeTz class/struct and a library of functions that operate on it. But in sql new value types have to be added out-of-band, either in the language implementation or via some extension mechanism (eg).
Surprisingly edgeql currently has the same problem, but only just. Edgeql has object types, but they are tied to their existence in a database table and can't be created as transient values. Edgeql also has tuple types which act as values, can have named fields, and are structurally typed:
gel_toy:main> with
a := <tuple<x: int64, y: str>>(42, "foo"),
b := <tuple<x: int64, y: str>>(42, "foo")
select {a, b};
{(x := 42, y := 'foo'), (x := 42, y := 'foo')}
Unfortunately there doesn't seem to be any way to name these tuple types in the schema, so you have to write them out in full in any function that uses them. There are type aliases for object types - it would be nice to extend them to all types. (Tracking issue).
multi sets
type A {
multi b: B;
}
type B {
multi c: str;
}
In the above schema, multi c: str allows repeated values:
gel_toy:main> insert B{c := {"a","a","a"}};
{
default::B {
id: 11327180-286a-11f0-bc57-870b66ba8f85,
},
}
But multi b: B does not:
gel_toy:main> insert A{b := {(select B), (select B), (select B)}};
error: QueryError: possibly not a distinct set returned by an expression for a link 'b'
┌─ <query>:1:10
│
1 │ insert A{b := {(select B), (select B), (select B)}};
│ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ You can use assert_distinct() around the expression to turn this into a runtime assertion, or the DISTINCT operator to silently discard duplicate elements.
If you want to allow repeated values, you have to make a separate table:
type AtoB {
required a: A,
required b: B,
}
In the imdb schema it would have been nice to model Principal as a multi link with link properties, rather than a separate table, like this:
type Person {
...
multi role: Title {
required ordering: int16;
required category: str;
optional job: str;
multi characters: str;
}
}
Unfortunately a given person can have multiple roles in a single title, and edgeql offers no way to opt into this behaviour for multi links. So we don't get to use the multi sugar here and we're stuck with the separate Principal table.
This seems like a waste of perfectly good sugar. It could be changed in a backwards compatible way by adding a repeated/distinct modifier to multi links, and making distinct the default if not specified.
This choice to force multi links to be sets also ties into some suboptimal choices in paths below.
inheritance
Edgeql object types support (multiple) inheritance from abstract types. Fields can link to abstract types:
abstract type X {
data: str;
}
type X1 extending X {}
type X2 extending X {
more_data: str;
}
type Y {
# This could link to an X1 or an X2!
required x: X;
}
Fields that exist in the abstract type are directly usable:
gel_toy:main> select X1{data};
{default::X1 {data: 'one'}}
gel_toy:main> select X2{data, more_data};
{default::X2 {data: 'two', more_data: 'extra'}}
gel_toy:main> select Y{x: {data}};
{
default::Y {x: default::X1 {data: 'one'}},
default::Y {x: default::X2 {data: 'two'}},
}
gel_toy:main> select Y.x.data;
{'two', 'one'}
But fields that exist only in subtypes can't be used without filtering by type first:
gel_toy:main> select Y.x.more_data;
error: InvalidReferenceError: object type 'default::X' has no link or property 'more_data'
┌─ <query>:1:11
│
1 │ select Y.x.more_data;
│ ^^^^^^^^^^ error
gel_toy:main> select Y.x[is X2].more_data;
{'extra'}
It's really annoying to model the same thing in sql databases. Probably you'd make separate tables y_to_x1 and y_to_x2 and then write a lot of unions.
-- Y.x.data
(
select data
from y, y_to_x1, x1
where y.id = y_to_x1.y_id
and y_to_x1.x_id = x1.id
)
union
(
select data
from y, y_to_x2, x2
where y.id = y_to_x2.y_id
and y_to_x2.x_id = x2.id
)
-- Y.x[is X2].more_data
select more_data
from y, y_to_x2, x2
where y.id = y_to_x2.y_id
and y_to_x2.x_id = x2.id
Also how would you write the integrity constraint that Y must be linked to exactly one of X1 or X2? Maybe via a trigger?
I am personally suspicious of modelling data using inheritance and I would prefer a closed sum type. As luck would have it, edgeql also supports union types.
union types
type X1 {
data: str;
}
type X2 {
data: str;
more_data: str;
}
type Y {
required x: X1 | X2;
}
With no abstract type in common, we might expect to have to filter down to a single type before accessing fields. But actually we can access any common fields immediately:
gel_toy:main> select Y.x.data;
{'two', 'one'}
gel_toy:main> select Y.x.more_data;
error: InvalidReferenceError: object type '(default::X1 | default::X2)' has no link or property 'more_data'
┌─ <query>:1:11
│
1 │ select Y.x.more_data;
│ ^^^^^^^^^^ error
What would have happened in X1.data and X2.data were different types? I would expect that either Y.x.data is an error or it produces a union type like str | int64. Surprisingly, the actual behaviour is that we can't even construct the union type!
type X1 {
data: str;
}
type X2 {
data: int64;
more_data: str;
}
error: cannot create union (default::X1 | default::X2) with property 'data' using incompatible types std::int64, std::str
┌─ /home/jamie/gel-toy/dbschema/default.gel:47:15
│
47 │ required x: X1 | X2;
│ ^^^^^^^ error
This feels like an implementation detail leaking out - I can't think of a reason that this restriction would be necessary.
Another restriction is that only object types can be unioned - there is no str | int64. This is probably forced by compiling to sql where columns have to have a single type. A union of two scalar types might be implementable as two nullable columns, but I imagine that would get tricky fast.
ddl
Inserts are an expression that return the inserted object.
gel_toy:main> insert Ingredient{name := "Apple"};
{
default::Ingredient {
id: 3468b0d8-29f5-11f0-bca9-4fad116fa833,
},
}
That means they can nested for inserting entire object graphs at once.
gel_toy:main> insert Recipe{
name := "Apple pie",
ingredients := assert_distinct({
(select Ingredient filter .name = "Apple"),
(insert Ingredient{name := "Flour"}),
(insert Ingredient{name := "Sugar"}),
}),
};
{
default::Recipe {
id: 77bc2ce8-29f5-11f0-957b-d3330904b903,
},
}
All the inserts in a given query are executed after the transaction finishes. So either all the inserts succeed or none do, and they're not visible during the query itself.
gel_toy:main> with pear := (insert Ingredient{name := "Pear"})
select Ingredient{name};
{
default::Ingredient {name: 'Apple'},
default::Ingredient {name: 'Flour'},
default::Ingredient {name: 'Sugar'},
}
gel_toy:main> select Ingredient{name};
{
default::Ingredient {name: 'Apple'},
default::Ingredient {name: 'Flour'},
default::Ingredient {name: 'Sugar'},
default::Ingredient {name: 'Pear'},
}
My immediate concern was that queries don't have a defined evaluation order, which might make it hard to say which side-effects should actually be executed. But, while I haven't investigated this thoroughly, the obvious paths to non-deterministic behaviour seem to have been ruled out:
gel_toy:main> select Ingredient{name := (insert Ingredient{name := "Ants"}).name} limit 0;
error: QueryError: mutations are invalid in a shape's computed expression
┌─ <query>:1:28
│
1 │ select Ingredient{name := (insert Ingredient{name := "Ants"}).name} limit 0;
│ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ To resolve this try to factor out the mutation expression into the top-level WITH block.
gel_toy:main> select Ingredient filter .id = (insert Ingredient{name := "Ants"}).id;
error: QueryError: INSERT statements cannot be used in a FILTER clause
┌─ <query>:1:33
│
1 │ select Ingredient filter .id = (insert Ingredient{name := "Ants"}).id;
│ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ To resolve this try to factor out the mutation expression into the top-level WITH block.
gel_toy:main> select <bool>{} or ((insert Ingredient{name := "Ants"}).name = "Ants"); // short-circuit?
{}
gel_toy:main> select Ingredient filter .name = "Ants";
{
default::Ingredient {
id: 7bd4a3da-29f7-11f0-8b4a-abab68ec8a7c,
},
}
Delete and update work similary.
It's not clear what happens when a single query issues multiple conflicting updates.
gel_toy:main> select Ingredient{name} filter .name like "Ants%";
{default::Ingredient {name: 'Ants'}}
gel_toy:main> for suffix in {"A","B","C"} union {
(update Ingredient set {name := .name ++ suffix})
};
{
default::Ingredient {
id: 4f483d84-29f9-11f0-b1fa-d3fc416888c2,
},
}
gel_toy:main> select Ingredient{name} filter .name like "Ants%";
{default::Ingredient {name: 'AntsA'}}
gel_toy:main> for suffix in {"C","B","A"} union {
(update Ingredient set {name := .name ++ suffix})
};
{
default::Ingredient {
id: 4f483d84-29f9-11f0-b1fa-d3fc416888c2,
},
}
gel_toy:main> select Ingredient{name} filter .name like "Ants%";
{default::Ingredient {name: 'AntsAC'}}
It looks something like 'first write wins', according to whatever accidental ordering we end up with on the underlying sql query. This should maybe be an error instead? (Tracking issue).
queries
grammar
I wanted to get a list of films an actor has been in. Here is what the process of writing that query looked like:
# get the principals
select .<person[is Principal]
# group them by title
group (
select .<person[is Principal]
) by .title
# take the first 10
group (
select .<person[is Principal]
) by .title
order by .key.title.startYear desc
limit 10
# ...oh, I can only order after a select
select (
group (
select .<person[is Principal]
) by .title
)
order by .key.title.startYear desc
limit 10
# pick out the title and roles
select (
group (
select .<person[is Principal]
) by .title
)
order by .key.title.startYear desc
limit 10
{
title := .key.title.primaryTitle,
roles := .elements.category,
}
# ...ugh, I can only shape at the start of a select
select (
select (
group (
select .<person[is Principal]
) by .title
)
order by .key.title.startYear desc
limit 10
)
{
title := .key.title.primaryTitle,
roles := .elements.category,
}
There are other similar sql-like grammar quirks. count is a function that can appear in any expression but distinct is an operator. group by has a using clause that is redundant with defining new fields.
All the other post-sql languages went with a more composable syntax where any operator can be applied in any order. If edgeql did the same, the final query might look like:
select .<person[is Principal]
group by .title
order by .key.title.startYear desc
limit 10
{
title := .key.title.primaryTitle,
roles := .elements.category,
}
I think this is much easier to read and write, and it's mostly a surface change to the grammar. PipeSQL shows that you can do this in a backwards-compatible way. It might be hard to combine with edgeql's implicit binding rules (below), but I also recommend removing those.
Another minor issue is that subqueries always require parens, but the error messages don't always point in that direction:
gel_toy:main> select Person {
others := select Person,
};
error: EdgeQLSyntaxError: Unexpected keyword 'SELECT'
┌─ <query>:2:11
│
2 │ others := select Person,
│ ^^^^^^ Use a different identifier or quote the name with backticks: `select`
│
= This name is a reserved keyword and cannot be used as an identifier
everything is a set
Every expression returns a set of values.
gel_toy:main> select 1;
{1}
Optional fields are represented by an empty set rather than a null value:
gel_toy:main> select (select Person{} offset 0 limit 1).birthYear;
{1961}
gel_toy:main> select (select Person{} offset 1 limit 1).birthYear;
{}
This means that any operation over multiple values throws away all the null values:
gel_toy:main> select Person{deathYear} limit 10;
{
default::Person {deathYear: {}},
default::Person {deathYear: {}},
default::Person {deathYear: 2016},
default::Person {deathYear: {}},
default::Person {deathYear: {}},
default::Person {deathYear: {}},
default::Person {deathYear: {}},
default::Person {deathYear: {}},
default::Person {deathYear: 1995},
default::Person {deathYear: {}},
}
gel_toy:main> select (select Person{deathYear} limit 10).deathYear;
{2016, 1995}
If you actually care about the null values you need to keep them inside objects. This seems like an easy source of bugs.
Actually, everything is not a set but a bag/multiset.
gel_toy:main> select {1,1,1};
{1, 1, 1}
The docs insist on using the word 'set' though, which seems unnecessarily confusing.
I definitely understand the appeal of "everything is a set/bag". Rel did this. I made the same choice in imp. But while I'm not confident that it's a mistake, I wouldn't make the same choice again.
The problem is that if you write a bunch of code assuming that you're dealing with a single value, and it turns out that you're not, then that code will behave weirdly. I've only been in the gel discord for a few weeks and I've already seen a couple of examples of this biting people.
For example, suppose we want to find all people whose birthYear is missing or obviously invalid:
gel_toy:main> select Person{} filter not exists(.birthYear) or .birthYear > 2025;
{}
This returns no results, even though we just saw an example above whose birthYear was missing. Let's break down how that filter gets evaluated:
gel_toy:main> select not exists({});
{true}
gel_toy:main> select <int64>{} > 2025;
{}
gel_toy:main> select {true} or <bool>{};
{}
The problem here is that exists applies to the set as a whole, but > and or are applied to the elements. And the missing birthYear doesn't have any elements. So the whole expression returns empty set which is falsey.
I think the correct response to a filter expression that can return zero or more booleans is "error". Either a type error at compile time, or at least a runtime error if the expression doesn't return exactly one element.
Edgeql does infer the possible cardinalities of sets and will give a warning for some cases. Eg it's fine with a filter expression returning zero booleans, but it will warn about returning more than one boolean.
warning: QueryError
┌─ <query>:1:24
│
1 │ select Person{} filter .primaryProfession = "director";
│ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ possibly more than one element returned by an expression in a FILTER clause ^^^^^^ possibly more than one element returned by an expression in a FILTER clause
You can silence this warning by making your intent explicit and asking for a runtime error if you're wrong:
gel_toy:main> select Person{} filter assert_single(.primaryProfession) = "director";
gel error: CardinalityViolationError: assert_single violation: more than one element returned by an expression
But you can make the same mistake elsewhere and it won't warn you.
gel_toy:main> select Person{salary := if .primaryProfession = "director" then 100000 else 40000} limit 3;
{
default::Person {salary: {40000, 100000, 40000}},
default::Person {salary: {40000, 100000, 40000}},
default::Person {salary: {40000}},
}
I actually wasn't expecting if to map over elements (because filter doesn't), so the above example isn't even wrong in the particular way I intended. It's bonus wrong.
To me "everything is a set" and "functions map over sets (except when they don't)" feel like nil punning in lisps. When it works it allows writing terser code. But when your assumptions are wrong or when the outside world changes, it allows obviously wrong code to run to completion and produce plausible results. Maybe the query above was correct when it was written, but then later primaryProfession was changed from a single field to a multi field, and now this code still runs but it's going to calculate the wrong staff budget.
It is almost certainly too much work to change the decision in edgeql now. But I'd recommend systematically fleshing out the warnings. Mapping functions over elements doesn't make sense for most functions. Expressions like one_value = many_values and maybe_zero_values or one_value are very likely to be mistakes. Yielding warnings for these will help keep them out of production, without breaking old queries or preventing quick sloppy queries in the repl.
If I was designing a query language from scratch I would just have types like Option<T> and Set<T>. I'd keep the same semantics as edgeql for paths, but otherwise an expression like .primaryProfession = "director" would be a type error. If I found that I often wanted to map a function over a set then maybe I'd add explicit spread or broadcast syntax like .primaryProfession@ = "director".
nested sets
Nested set expressions are flattened:
gel_toy:main> select {1,{1,{1}}};
{1, 1, 1}
But nested sets can appear in objects:
gel_toy:main> for a in {1,2} union (
select {a := {a,a,a}}
);
{Object {a: {1, 1, 1}}, Object {a: {2, 2, 2}}}
So it's not a technical limitation - edgeql is capable of transforming queries with nested sets into sql. The implicit flattening is probably more set-punning, and again I would prefer to be explicit about intentions. Write {a, b} when you intend to produce a set with two elements, and use some kind of spread syntax {a@, b@} when what you actually want is the union of two sets.
.link
If we have a Principal and we want to get the corresponding persons name, we could write it out as an explicit join:
name := (
select Person
filter Person = Principal.person
).primaryName
But following links (aka foreign keys) is such a common case that it's worth having syntax sugar for it:
name := Principal.person.primaryName
This is great. No complaints.
aRegular joins are still available when you need them, but most of your queries will just use this syntax sugar. And it is just sugar - there aren't actually any nested objects in the underlying postgres schema.
main=# \d "Principal"
Table "public.Principal"
Column | Type | Collation | Nullable | Default
-----------+----------+-----------+----------+---------
id | uuid | | not null |
__type__ | uuid | | not null |
category | text | | not null |
job | text | | |
ordering | smallint | | not null |
person_id | uuid | | not null |
title_id | uuid | | not null |
.<link
If we're starting at a Principal and we want the corresponding Person, we can use .person. But what if we're starting at a Person and we want a list of Principals? We could write a regular join:
principals := (
select Principal
filter Principal.person = Person
)
But there is sugar for following links backwards too. It looks like:
principals = Person.<person[is Principal]
This is actually two pieces of syntax:
- The syntax
.<personreturns any object of any type that has a link that looks likeperson: Person. - The type intersection syntax
[is Principal]keeps only the objects of typePrincipal.
With union types I would have preferred to directly specify the link we're following, something like .(Principal.person). But given the presence of inheritance and abstract types, it's maybe useful to have the ability to follow multiple links at once (eg from a single parent type, following links backwards to multiple child types).
computed properties
Suppose we got tired of writing Person.<person[is Principal] all the time. We can add it to the schema instead as a computed property:
type Person {
...
principals := .<person[is Principal];
}
Now we can write Person.principals instead.
Whenever I have to write a lot of sql queries over the same schema I end up writing the same shit over and over again. Being able to push common patterns back down into the schema is a great idea.
This is also a kind of logical data independence. The logical schema now has a link from Person to Principal that is not present in the physical schema. If we wanted to change the physical schema to have a link from Person to Principal instead and make the other direction the computed property, we wouldn't have to change any of our queries. This isn't really possible in sql.
paths
When following a chains of links/properties, the operation is applied for each element of the set and then the results are unioned together:
gel_toy:main> with peeps := (select Person{} limit 3)
select peeps.primaryProfession;
{
'actress',
'writer',
'producer',
'miscellaneous',
'producer',
'miscellaneous',
'production_designer',
}
This is why it's worth making everything a bag rather than a set - it makes aggregation much simpler:
gel_toy:main> with peeps := (select Person{} limit 3)
select count(peeps.primaryProfession);
{7}
gel_toy:main> with peeps := (select Person{} limit 3)
select count(distinct peeps.primaryProfession);
{5}
If peeps.primaryProfession was a set then we could effectively only write the second query. If we wanted to be able to write the first query we would have to make a set that preserves the uniqueness:
gel_toy:main> with peeps := (select Person{} limit 3)
select count((
for peep in peeps union (
for profession in peep.primaryProfession union (
select {id := peep.id, profession := profession}
)
)
))
{7}
Both rel and imp had to do this. It's not just annoying but slower - the query engine has to materialize the whole set to check for duplicate rows, even though the whole reason we added those extra columns was to prevent duplicate rows.
It's even worse for other aggregates like sum. We wouldn't be able to write sum(peeps.salary) because some people might have the same salary, but we pass multiple columns to sum because we need to specify which one to actually sum over. So we would end up writing something like sum_with(peeps, fn (peep) => peep.salary).
So if you're going to do "everything is an X", I'm pretty confident that bags are a better choice than sets and edgeql made the right call here.
Unfortunately, edgeql also applies an implicit distinct to paths when the field is an object type, so for all the but the simplest queries we're effectively back to sets:
gel_toy:main> select Employee{role: {name, salary}};
{
default::Employee {
role: default::Role {name: 'director', salary: 100000},
},
default::Employee {
role: default::Role {name: 'director', salary: 100000},
},
default::Employee {
role: default::Role {name: 'actor', salary: 200000},
},
default::Employee {
role: default::Role {name: 'actor', salary: 200000},
},
default::Employee {
role: default::Role {name: 'actor', salary: 200000},
},
}
gel_toy:main> select Employee.role.salary;
{100000, 200000}
If you want to aggregate over links like this, you need to use an explicit for expression for each level of link traversal to avoid the implicit distinct:
gel_toy:main> for employee in Employee union (select employee.role.salary);
{100000, 100000, 200000, 200000, 200000}
gel_toy:main> select sum((for employee in Employee union (select employee.role.salary)));
{800000}
The argument in #2054 is that the implicit distinct is usually what users want and allows for more efficient joins. But given the interaction with aggregation I'm not convinced.
Also the implicit distinct is only applied to links and not properties, so to understand the behaviour of foo.bar you have to know whether bar is link or a property.
One backwards-compatible option might be to introduce a separate operator .. that doesn't perform the implicit distinct, so we could write eg sum(Employee..role.salary) instead of the for expression above. But if starting from scratch I'd have preferred for . to preserve duplicates and use sum(distinct(Employee.role).salary) if that's actually the behaviour we want.
for
A for expression loops over the elements of a bag, evaluates an expression for each element, and unions the results together.
gel_toy:main> for a in {1,5,9} union (
select {a, a + 1}
);
{1, 2, 5, 6, 9, 10}
This is like a dependent subquery or lateral join in sql. This comes up all the time in complex queries and it's great to have it as a simple expression with no quirks.
The semantics are partially redundant with select though - we only need for because select can't replace the object it's looping over, only reshape it. If we went with more composable operators like prql then we could write queries like:
from a := {1,5,9}
filter a % 5 != 0
select b := {a, a + 1}
order by b
limit 3
To do the same in edgeql today you would have to write:
select b := (
for a in (
select a := {1,5,9}
filter a % 5 != 0
) union (
select {a, a + 1}
)
)
order by b
limit 3
implicit bindings
What do you expect this query to return?
select Person {
primaryName,
others := (select Person{primaryName} limit 3),
}
limit 3
You probably didn't expect this:
{
default::Person {
primaryName: 'Alan Jay',
others: default::Person {primaryName: 'Alan Jay'},
},
default::Person {
primaryName: 'Angela Jay',
others: default::Person {primaryName: 'Angela Jay'},
},
default::Person {
primaryName: 'Antony Jay',
others: default::Person {primaryName: 'Antony Jay'},
},
}
In select you can explicitly give a name to the object that will be available in later expressions.
select person := Person
filter is_cool(person.birthYear)
But if you don't give an explicit binding, edgeql will create an implicit binding, shadowing the name of the set you're selecting.
select Person
filter is_cool(Person)
// is equivalent to
select Person := Person
filter is_cool(Person)
So the confusing query above is equivalent to:
select person := Person {
primaryName,
others := (select person{primaryName} limit 3),
}
limit 3
Sql also has this feature of reusing a relation name as a row name, but you can't make the same mistake in sql because relation names and row names are in separate scopes.
To work around shadowed bindings, edgeql offers the detached keyword to resolve bindings in the global namespace instead of the local namespace:
gel_toy:main>
select Person {
primaryName,
others := (select detached Person{primaryName} limit 3),
}
limit 3;
{
default::Person {
primaryName: 'Alan Jay',
others: {
default::Person {primaryName: 'Alan Jay'},
default::Person {primaryName: 'Angela Jay'},
default::Person {primaryName: 'Antony Jay'},
},
},
default::Person {
primaryName: 'Angela Jay',
others: {
default::Person {primaryName: 'Alan Jay'},
default::Person {primaryName: 'Angela Jay'},
default::Person {primaryName: 'Antony Jay'},
},
},
default::Person {
primaryName: 'Antony Jay',
others: {
default::Person {primaryName: 'Alan Jay'},
default::Person {primaryName: 'Angela Jay'},
default::Person {primaryName: 'Antony Jay'},
},
},
}
But this only solves the problem if the name you shadowed was in the global scope. If you shadowed eg a with binding then detached can't help you:
gel_toy:main>
with people := (select Person)
select people {
primaryName,
others := (select detached people{primaryName} limit 3),
}
limit 3
error: InvalidReferenceError: object type or alias 'default::people' does not exist
┌─ <query>:4:30
│
4 │ others := (select detached people{primaryName} limit 3),
│ ^^^^^^ error
Anyway, in most cases none of this is necessary anyway because you don't often need to refer to the object as a whole. If you only care about the fields of the object then you don't need the name at all:
select Person
filter is_cool_year(.birthYear)
My suggestion would be to remove implicit bindings entirely. They aren't needed in many cases, and in some cases they are a footgun. In the cases where they are needed they can always be replaced by an explicit binding.
In some of the cases where implicit bindings save thinking up a name, they could be replaced by allowing . to refer to the current object, in analogy with the way .birthYear refers to a field of the current object.
select Person
filter is_cool(.)
shapes
Shape expressions are weird.
By default, you only get the id field in the output.
gel_toy:main> select Person{} limit 1;
{default::Person {id: fdb75024-22e9-11f0-be4b-539f5da48fe1}}
You can ask for other fields.
gel_toy:main> select Person{primaryName, birthYear} limit 1;
{default::Person {primaryName: 'Roshie Jones', birthYear: {}}}
But we're not actually producing a new value - the asked-for fields don't remain visible in other expressions.
gel_toy:main> with peeps := (select Person{primaryName, birthYear} limit 1)
select peeps;
{default::Person {id: fdb75024-22e9-11f0-be4b-539f5da48fe1}}
But if we alter or add a field, that does change the value.
gel_toy:main> with peeps := (select Person{primaryName := "Replaced!", nonsense := 42} limit 1)
select peeps{primaryName, nonsense};
{default::Person {primaryName: 'Replaced!', nonsense: 42}}
The shape expression is actually doing two different things:
- It can replace or add fields to the object.
- It defines which set of fields are printed in the result - the 'shape' of the object.
The confusion comes from the fact that if we refer to the same object in another select expression, it resets the shape.
I suspect the shape concept comes from adopting sql-style select grammar. The shape expression comes before filter/order expressions, but the latter might want to refer to fields that we don't want in the output.
select Person{primaryName, age := 2025 - .birthYear}
filter .age < 25 and "director" in .primaryProfession
But this isn't a problem with composable operators:
from Person
age := 2025 - .birthYear
filter .age < 25 and "director" in .primaryProfession
select {primaryName, age}
Perhaps this is harder in deeply nested structures, but I can't come up with a compelling example.
functions
They exist, the syntax isn't onerous, and because of the declaritive schema they're not annoying to manage.
function filter_tsv_null(s: str) -> optional str
using (
if (s = "\\N") then <str>{} else s
);
They have some limitations, which I imagine are inherited from compiling them to postgres functions. Notably, unlike builtin functions, user-defined functions can't take sets as parameters. You can work around this by passing an array, but that's going to actually materialize an array in memory, so you can't efficiently write your own aggregate functions.
Unfortunately I don't see any easy workaround for this while still relying on postgres functions. They could implement functions instead in the edgeql compiler via inlining, but this can cause exponential amounts of code to be generated in some edge cases (A has two calls to B, B has two calls to C, etc).
conclusions?
I think the fundamental goal of the language is sound. There are many details I would change. Some of those can be changed in a backwards compatible way, and the team seems open to experimenting with them. Other decisions they are probably stuck with at this point. None of them are existential though. You can get things done.
All other things being equal, I would absolutely choose gel over sql. The declarative schema, computed properties, saner semantics, join sugar etc are all a noticeable improvemnt over the status quo.
But all other things are not equal, at least at this point. The core problem is:
- It's a small team tackling a really large surface area, leading to inevitable gaps.
- The way gel is architected, it's not always possible to work around the gaps.
The process of loading the imdb data illustrates this perfectly. I first loaded it into vanilla postgres using COPY which took about six minutes, including time spent building indexes and normalizing json columns.
I then tried inserting the same data into gel through edgeql insert statements and, at the rate it was going, it would have taken 68 hours.
Most of this seems to be encoding overhead going through javascript -> gel -> postgres. By passing the raw tsv through to postgres in chunks I was able to reduce the load time to 9 hours, at the cost of doing my own tsv parsing in edgeql:
// import.ts
await client.transaction(async (tx) => {
for await (const chunk of readTsvChunks("./data/name.basics.tsv")) {
await insertPersons(tx, { tsv: chunk });
}
});
// insertPersons.edgeql
for line in array_unpack(std::str_split(<str>$tsv, "\n")) union (
with
row := std::str_split(line, "\t")
insert Person {
nconst := row[0],
primaryName := row[1],
birthYear := std::to_int16(filter_tsv_null(row[2])),
deathYear := std::to_int16(filter_tsv_null(row[3])),
primaryProfession := array_unpack(std::str_split(filter_tsv_null(row[4]), ",")),
knownForTitles := array_unpack(std::str_split(filter_tsv_null(row[5]), ",")),
}
);
Since gel is built on postgres it should be possible to bulk import data directly. Unfortunately, the underlying postgres instance is full of tables named things like edgedbpub."90500e3b-246b-11f0-855f-cd9e706a7359" (presumably to handle their branching and versioning features). So you send sql queries via a protocol wrapper that picks a specific branch and provides the illusion of sane naming. But that wrapper doesn't seem to handle the COPY command correctly:
main=# \d
List of relations
Schema | Name | Type | Owner
--------+--------------------------+-------+----------
public | Person | table | postgres
public | Person.knownForTitles | table | postgres
public | Person.primaryProfession | table | postgres
(3 rows)
main=# COPY Person
FROM '/home/jamie/gel-toy/data/name.basics.tsv'
DELIMITER E'\t'
CSV HEADER;
ERROR: unknown table `person`
LINE 1: COPY Person
^
main=# COPY "Person"
FROM '/home/jamie/gel-toy/data/name.basics.tsv'
DELIMITER E'\t'
CSV HEADER;
ERROR: syntax error at or near "FROM"
LINE 1: COPY "Person"
^
So I can't go through gel and I can't go around it.
This particular issue is fixable but issues like this are inevitable. Sql performance can already be finicky when using sql directly, let alone as a compiler target. Compiling to sql from a query language with a entirely different model makes that even worse. There is guaranteed to be a long tail of surprises:
> time psql -c 'with peeps as (select * from person limit 3) select job from peeps join principal using (nconst)' > /dev/null
________________________________________________________
Executed in 12.86 millis
> time gel query 'with peeps := (select Person{} limit 3) select peeps.<person[is Principal].job;' > /dev/null
________________________________________________________
Executed in 14.51 secs
I don't know a way around this. Sql is a terrible compiler target. Building your own query engine is a huge investment. We don't have a reusable oltp query engine yet. There are no good choices.
But if gel was just a postgres extension that created a readable schema, if I could be guaranteed that I could always just use regular sql when needed, it would at least feel less risky.
There is some trickiness here, for why we don't/can't expose unfiltered raw SQL. The crux of it is that we have data invariants that aren't enforced by PG constraints of any sort, but that do get enforced by construction by our compiler:
- Required multi pointers always have at least one element. Enforced by explicit checks when doing INSERT/UPDATE in the compiler.
- Links always point to a real object. We don't use foreign keys (partially for minor optimization reasons, and partially because of what you observed for the integrity constraints about unions/inheritance).
- Ids are exclusive across all tables, but we don't do any enforcement of this except for explicitly user specified ids. Otherwise we rely on the odds of uuids colliding being muuuuuuch lower than the odds of basically anything else going wrong.
p.s.
How many layers of machinery do we even need here? Unlike olap queries, which benefit massively from sophisticated query optimizations, most oltp queries just aren't that hard to execute.
Due to the nesting in most edgql queries, all the query plans I've looked so far have were just nested loops on top of index lookups. Most of the machinery isn't even getting used, but we still have to deal with all the complexity and surprises from those layers.
Do the benefits of an oltp query language actually outweigh the costs?