(This is part of a series on the design of zest. See the list of posts here.)
Suppose I want to implement an interactive language - one where code is often run immediately after writing. Think scientific computing, database queries, system shells etc. So we care about both compile-time and run-time performance because we'll usually experience their sum.
A traditional switch-based bytecode interpreter is very easy to implement and very portable, but typically leaves 10-1000x run-time performance on the floor compared to a good optimizing compiler.
On the other hand, using an AOT-focused compiler like llvm or gcc can often leave 10-1000x compile-time performance on the floor compared to a simple interpreter.
It would be nice to find a sweet spot somewhere in the middle of the pareto curve. Let's say that for any given program we'd like the combined compile-time and run-time to always be within 5x of (pure) cpython AND within 5x of clang. So on small data our programs start up quickly, but on large data they still run reasonably quickly.
Also let's make life even harder and also demand:
- Only 1-2 years of dev effort to implement.
- Predictable, explainable performance.
- A small, embedabble runtime.
- Support for repl / incremental programming (ie adding one function shouldn't require stopping the process and re-compiling the entire project).
- Support for debugging and profiling.
This isn't going to be one of those blogvertisements where I describe the problem as a prelude to selling the solution. I don't know yet whether this is a feasible set of demands.
pruning
Some options I can immediately discard:
- LLVM has unacceptable compile times.
- Tracing JITs produce unpredictable performance, and seem to be time-consuming to implement.
- Futumura projections (eg truffle, rpython) haven't seen much uptake and come with huge opaque runtimes.
language
Performance certainly depends on the language we're implementing. There's not much to gain by compiling a language like python - it's all hash-table lookups and dynamic dispatch. I can see all the bodies on that hill.
So let's say we have a language that provides at least the basic affordances for a performant implementation:
- Ability to use static dispatch, static field offsets and stack allocation.
- Control over memory layout - at minimum being able to express arrays-of-structs without pointer soup.
fast interpreters
Direct threaded interpreters can be pretty fast. Eg wasm3 runs ~30x slower than a good wasm compiler and is written in ~18kloc of fairly portable c. That's especially impressive given that wasm is such a low-level bytecode. Could an interpreter for a language with higher-level operations make it within the 5x I'm looking for?
The interpreters with the lowest overhead are usually written in assembly to avoid the overhead of c calling conventions. Unfortunately I don't know of any in this style that are written for compiler-friendly languages, so it's hard to judge the relative performance and thus whether it's worth the additional work compared to a threaded interpreter.
Interpreter generators exist which take a high-level description of an interpreter and generate the assembly for the core interpreter. As far as I know none of these are particularly production-ready yet, but it's worth keeping an eye on eg deegen.
existing compilers
LLVM is not the only game in town, but most of the competition is immature.
Cranelift seems to be the most battle-tested alternative. It's runtime performance is often close to LLVM's. In this paper linked from it's homepage comparing wasm backends, the cranelift backends have compile-times ~10x less than that of llvm (but still ~100x copy-and-patch, which itself has longer startup times than an interpreter).
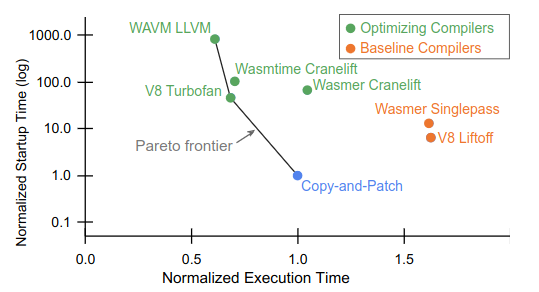
One thing to note on that graph is the scale of the axes. It's possible to gain a lot on compile-time performance without giving up much on run-time performance. For most industrial usecases this is a terrible tradeoff because we compile code once and ship it to hundreds of thousands of devices. But for interactive programming the tradeoffs are very different and mostly underserved, which is what might make these demands plausible.
custom compilers
Here's a set of graphs from the umbra database:
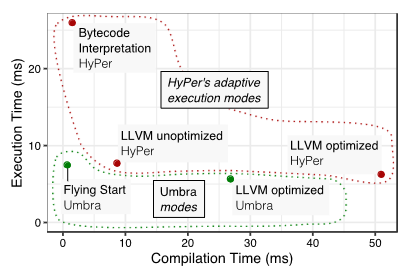
'Flying start' is a query compiler written entirely from scratch which produces ~100x better compile-time than their llvm-based query compiler, at the cost of only 1.2x worse run-time. This is well worth the tradeoff for one-off queries:
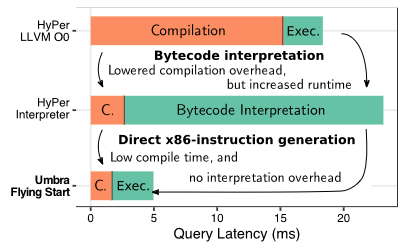
The entire compiler is ~24kloc for x86. The recent arm backend adds another 8kloc. That's not too intimidating, but it's not obvious whether writing a similar compiler for an entire programming language would be as approachable.
We can see some similar sweetspots when comparing wasm backends:
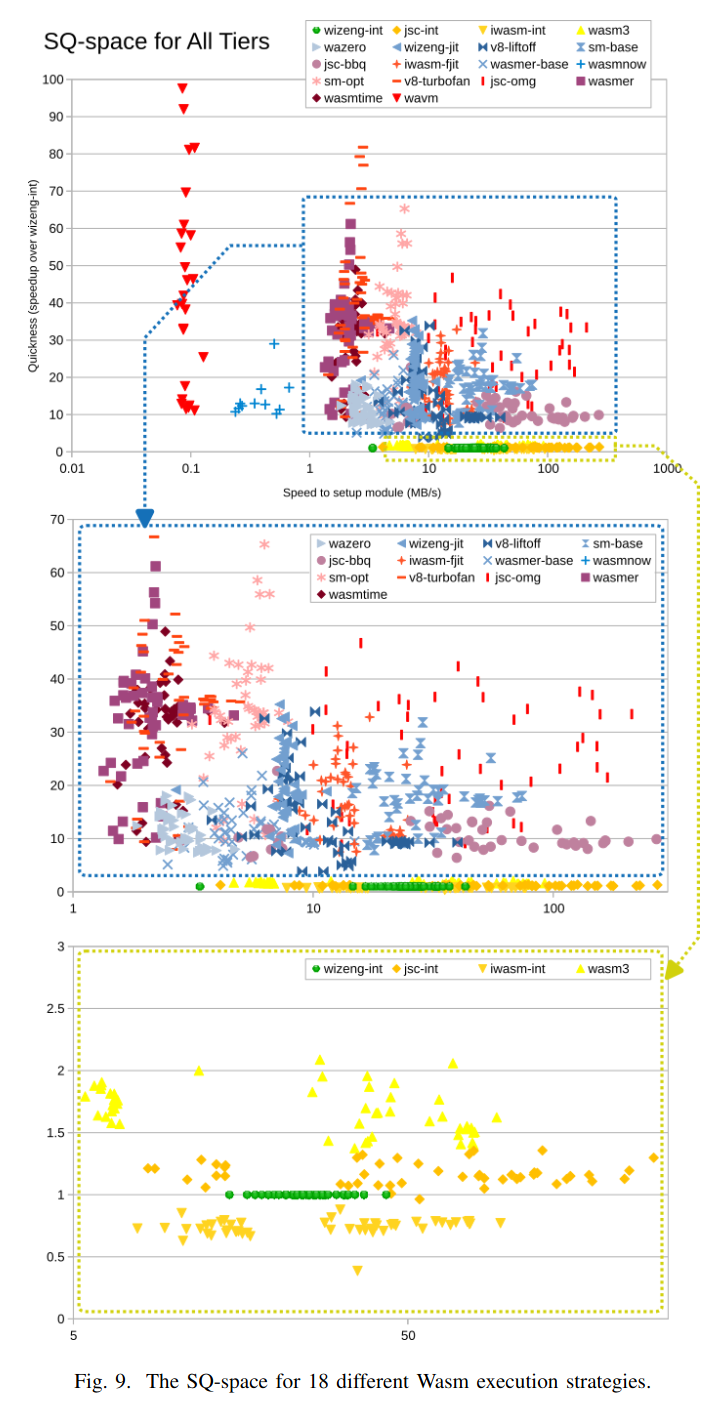
Many of the baseline compilers in that blue box fit in the 5x-worse sweetspot. But again, not clear whether this will generalize. The wasm in these experiments has already been through a lot of optimization work AOT.
I didn't find any similar experiments for actual programming languages.
wasm
Webassembly is appealing as a backend for a custom compiler:
- I'd want to be able to target wasm anyway to run code in browsers.
- There's a wealth of backends for running wasm, many of which focus on fast compile-times.
- It's well-specified and easy to emit.
On the other hand:
- Linking basically only exists for languages using the c ffi, via a separate spec that embeds custom sections. The wasm component model still seems pretty far away.
- There doesn't seem to be a consensus on debug info. The compilers I've tried produce dwarf but the firefox and chrome debuggers expect source maps. (There is a beta extension for chrome to read dwarf, which I haven't tried yet.)
- I'm not sure yet which backends have support for editing/reloading code. This might be possible in js backends by adding a new module which imports the old module's memory and edits the function table. (I also haven't yet tested the overhead of calling functions through imports, which requires bouncing into the js runtime.)
- Only a small subset of vector instructions are supported which limits the options for vector kernels, hashing, cryptography etc.
tiers
In this talk djb argues that most code doesn't benefit from heavy optimization, and that the remaining hot spots would benefit from more explicit control.
This is thematically compatibly with:
- Two-language ecosystems like python/numpy where interpreted python code is used to orchestrate calls into heavily optimized c kernels.
- OLAP databases where the bulk of input data is filtered or aggregated by heavily optimized columnar scans.
- Tiered jit compilers like v8 where most code runs either in an interpreter or through a single-pass baseline compiler, and only hotspots run through the optimizing compiler.
Vectorized interpreters are really appealing because they're so cost-effective. You get all the benefits of an interpreter (fast startup, easy tooling), and as long as your code fits the pre-compiled kernels you get the performance of an aggressively compiled language.
But some code doesn't fit your existing kernels, and some code just doesn't vectorize well at all. In scientific computing people talk about the two-language problem. In databases, vectorized interpreters struggle with OLTP queries and can't efficiently integrate user-defined functions. Even when code can be written in a vectorized style it's often awkward.
(In imp I explored how much a relational language could be written in a scalar style while still being automatically translated to vectorized style. I could cover most of core SQL but still kept running into functions at the edges that are inherently scalar: custom aggregates, functions on strings/arrays, transitions in state machines etc.)
This does suggest one plausible strategy though: Have two backends for the same language and support mixing both within a single program. Glue code can go through the low-latency, barely-optimizing backend for quick startup times, but hot spots and vector kernels can go through the high-latency, aggressively optimizing backend. This is more or less what tiered jit compilers are doing, except that the performance can be made predictable by putting the tier decision in the programmers hands.
The downside, of course, is that now you have to write two backends. So they better both be pretty easy to write. Spidermonkey is interesting in this regard, because it's baseline interpreter and baseline jit compiler share a lot of code.
next
I have a wealth of unknowns.
I've written a babys-first-wasm-compiler (next post) which answered some questions about linking and abi choices, but isn't suitable for performance experiments because it's a weird toy language for which no interesting code exists. Probably the most useful experiment would be to write a similar compiler for an existing language that already has a reasonable bytecode interpreter. Ocaml or erlang might be good choices.
It's probably worth doing some kind of benchmarks with tcc, go, ocaml, the new zig backends etc to get a sense whether it's practical to just copy an existing architecture.
Julia comes close to being a good interactive language in this sense, but it plagued by long compile times when importing modules (this has been somewhat reduced by pervasive precompilation, but it's still painful). I'd like to know how much of this is llvm being slow vs compiling everything at O3 vs julia's frontend being slow vs monomorphization generating too much code. If julia were mostly interpreted would the compile times be reasonable, or does monomorphization already blow the budget?
I should read more about how both umbra and spidermonkey work, since those are the closest I've seen to hitting the sweetspot. I need to get a sense of how much work it would take to do a similar quality single-pass compiler for a simple imperative language. The comparison here is the only input I have at the moment:
In short, the native-code compiler for OCaml is about half the size of its interpreter, and so is presumably much more "naive", in the sense that it required much less effort to implement. But it still performs one to two orders of magnitude better than the bytecode interpreter.
I don't know how fast an interpreter for a performance-friendly language could be. All the examples I know of are for very dynamic languages like lua or javascript. The ocaml interpreter is much slower than the ocaml compiler, but neither are state-of-the-art.
I also have no idea how painful it is to provide debugger support for a custom compiler (either via emitting dwarf or by writing a custom compiler, as is planned for the guile scheme wasm backend). I'm not even really sure how best to find out. Maybe I should try to emit dwarf for my toy compiler?