Kevin Lynagh and I spent some time playing around with zig on nrf52 boards. He's written about the experience here. I wanted to additionally highlight the api we used for memory-mapped IO registers because it shows off some nice features of zig.
An MMIO register is just an address in memory where reads and writes are interpreted specially by the hardware. For example, on the nRF52833 board writing the value 0b11 to address 0x708 will set the 3rd GPIO pin to output mode and disconnect the input buffer.
The list of available registers is documented in a massive pdf for each board. The same information also exists in an accompanying xml file which we can use to generate a nice typed api. So the question is what do we want the api to look like?
Fundamentally, an MMIO register is just a pointer to some specific address in memory:
const Register = struct {
raw_ptr: *u32,
pub fn init(address: usize) Register {
return Register{ .raw_ptr = @intToPtr(*u32, address) };
}
pub fn read_raw(self: Register) u32 {
return self.raw_ptr.*;
}
pub fn write_raw(self: Register, value: u32) void {
self.raw_ptr.* = value;
}
}
It's important though that all reads and writes to the pointer happen in a single instruction so that the hardware doesn't see half a write. We also have to be careful that reads and writes are never optimized away by the compiler because it thinks that they don't affect the rest of the program. We can guarantee both of these with the volatile keyword.
const Register = struct {
raw_ptr: *volatile u32,
pub fn init(address: usize) Register {
return Register{ .raw_ptr = @intToPtr(*volatile u32, address) };
}
pub fn read_raw(self: Register) u32 {
return self.raw_ptr.*;
}
pub fn write_raw(self: Register, value: u32) void {
self.raw_ptr.* = value;
}
}
The values in these registers are often interpreted as packed bitfields:
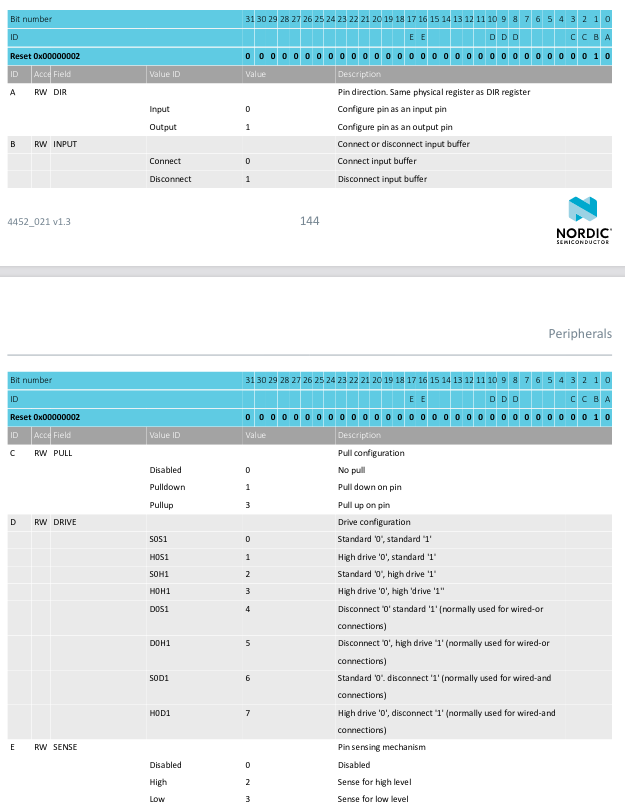
Zig can represent these kinds of bitfields directly:
const pin_cnf_val = packed struct {
dir: packed enum(u1) {
input = 0,
output = 1,
} = .input,
input: packed enum(u1) {
connect = 0,
disconnect = 1,
} = .disconnect,
pull: packed enum(u2) {
disabled = 0,
pulldown = 1,
pullup = 3,
} = .disabled,
_unused4: u4 = 0,
drive: packed enum(u3) {
s0s1 = 0,
h0s1 = 1,
s0h1 = 2,
h0h1 = 3,
d0s1 = 4,
d0h1 = 5,
s0d1 = 6,
h0d1 = 7,
} = .s0s1,
_unused11: u5 = 0,
sense: packed enum(u2) {
disabled = 0,
high = 2,
low = 3,
} = .disabled,
_unused18: u14 = 0,
};
There are a whole bunch of features on show here:
- The fields of a
packed structare always laid out in memory in the order they are written, with no padding. u3is a 3-bit unsigned integer.- A
packed enum(u3)is an enum stored as a 3-bit unsigned integer. - Zig types can be used anonymously, so we don't need to name the various enums here if we don't want to.
- Struct fields can be given default values eg
input = .disconnect.
We can check that this layout is correct at compile time:
comptime {
assert(@bitSizeOf(pin_cnf_val) == @bitSizeOf(u32));
}
We could just make the struct field be raw_ptr: *volatile pin_cnf_val but this won't work for all registers - some registers have different interpretations depending on whether you are reading or writing, so we need different types for reading and writing.
We can handle this by writing a function that takes the read type and the write type as arguments, and returns a type describing the register:
pub fn Register(comptime Read: type, comptime Write: type) type {
return struct {
raw_ptr: *volatile u32,
// The type being returned inside this function doesn't have a name yet when it's being created
// so we have to refer to it using `@This()`
const Self = @This();
pub fn init(address: usize) Self { ... }
pub fn read_raw(self: Self) u32 { ... }
pub fn write_raw(self: Self, value: u32) void { ... }
pub fn read(self: Self) Read {
return @bitCast(Read, self.raw_ptr.*);
}
pub fn write(self: Self, value: Write) void {
self.raw_ptr.* = @bitCast(u32, value);
}
}
}
This is how generics work in zig!
Here's the earlier example rewritten with this nice new api:
const pin_cnf_2 = Register(pin_cnf_val, pin_cnf_val).init(0x708);
pin_cnf_2.write(.{
.dir = .output,
.input = .disconnect,
});
The .{ ... } is an anonymous struct and the .output and .disconnect are anonymous enums. These have their own unique type, but are coercible to any struct/enum with the same structure. This means the user of our api doesn't have to import any of these types or even remember their names.
Here is the generated code:
000100e4 <__unnamed_1>:
100e4: 00000003 andeq r0, r0, r3
000200e8 <_start>:
200e8: f240 00e4 movw r0, #228 ; 0xe4
200ec: f2c0 0001 movt r0, #1
200f0: 6800 ldr r0, [r0, #0]
200f2: f44f 61e1 mov.w r1, #1800 ; 0x708
200f6: 6008 str r0, [r1, #0]
200f8: 4770 bx lr
I'm not sure why it loads the 3 from a constant section instead of just writing it directly to r0. But we can at least see that the str is a single instruction, as desired.
It's pretty common to want to read a value from a register, modify some fields and then write it back. So let's add a method to do that:
pub fn Register(comptime Read: type, comptime Write: type) type {
return struct {
...
pub fn modify(self: Self, new_value: anytype) void {
if (Read != Write) {
@compileError("Can't modify because read and write types for this register aren't the same.");
}
var old_value = self.read();
const info = @typeInfo(@TypeOf(new_value));
inline for (info.Struct.fields) |field| {
@field(old_value, field.name) = @field(new_value, field.name);
}
self.write(old_value);
}
};
}
It's used very similarly to the write method:
pin_cnf_2.modify(.{
.dir = .output,
.input = .disconnect,
});
The only difference is that instead of assigning default values to fields that aren't mentioned, it uses the values that are currently in the register.
There is a lot going on in the implementation:
- If the read and write types aren't the same then this function doesn't make sense. We check at compile time and emit a nice error message with a call stack if the types don't match.
@typeInforeturns a data structure containing information about a type. We can use this to check what fields are mentioned in the anonymous struct type.- The type info is known at compile time, so we can use
inline forto unroll a loop over the list of fields. @field(foo, "bar")means the same asfoo.bar, allowing us to refer to fields with a string name that is known at compile time.
All of the metaprogramming is compiled away, leaving us with:
000200e4 <_start>:
200e4: b082 sub sp, #8
200e6: f44f 60e1 mov.w r0, #1800 ; 0x708
200ea: 6801 ldr r1, [r0, #0]
200ec: 0a0a lsrs r2, r1, #8
200ee: f8ad 2000 strh.w r2, [sp]
200f2: 0e0a lsrs r2, r1, #24
200f4: f041 0103 orr.w r1, r1, #3
200f8: f88d 2002 strb.w r2, [sp, #2]
200fc: f88d 1007 strb.w r1, [sp, #7]
20100: f89d 1007 ldrb.w r1, [sp, #7]
20104: f240 720b movw r2, #1803 ; 0x70b
20108: 7001 strb r1, [r0, #0]
2010a: f8bd 0000 ldrh.w r0, [sp]
2010e: f89d 1002 ldrb.w r1, [sp, #2]
20112: 7011 strb r1, [r2, #0]
20114: f240 7109 movw r1, #1801 ; 0x709
20118: 8008 strh r0, [r1, #0]
2011a: b002 add sp, #8
2011c: 4770 bx lr
More bitshifting than I would have liked to see in the final code, but there's certainly no leftover metaprogramming.
This isn't a sufficiently-smart-compiler thing either. The rules for what is evaluated at compile-time are pretty simple:
- function arguments prefixed with
comptimemust be known at compile time at the callsite - blocks wrapped in
comptime { ... }are evaluated at comptime - if the argument to
iforswitchdoesn't refer to any variables not known at compile time, the correct branch is inlined - the argument to
inline fororinline whilemust be known at compile time and their body is unrolled - some builtin functions like
@fieldrequire their arguments to be known at compile time
After all of this compile-time evaluation and loop unrolling, the result is still statically type-checked. So if we typo a field name we get a reasonable error at compile time:
./test.zig:39:17: error: no member named 'inpot' in struct 'pin_cnf_val'
@field(old_value, field.name) = @field(new_value, field.name);
^
./test.zig:100:21: note: called from here
pin_cnf_2.modify(.{
^
./test.zig:98:25: note: called from here
export fn _start() void {
^
This puts zig in an interesting spot in the space of language design. It can do the kinds of metaprogramming available in many dynamic languages - using the language itself rather than switching to a clunky type language. But we can easily guarantee that the metaprogramming is compiled away and the resulting code is statically type-checked. And the whole thing compiles to a single binary that doesn't even depend on libc - the stripped binary for the first example above is 872 bytes.