Here are two pages from the internet movie database:
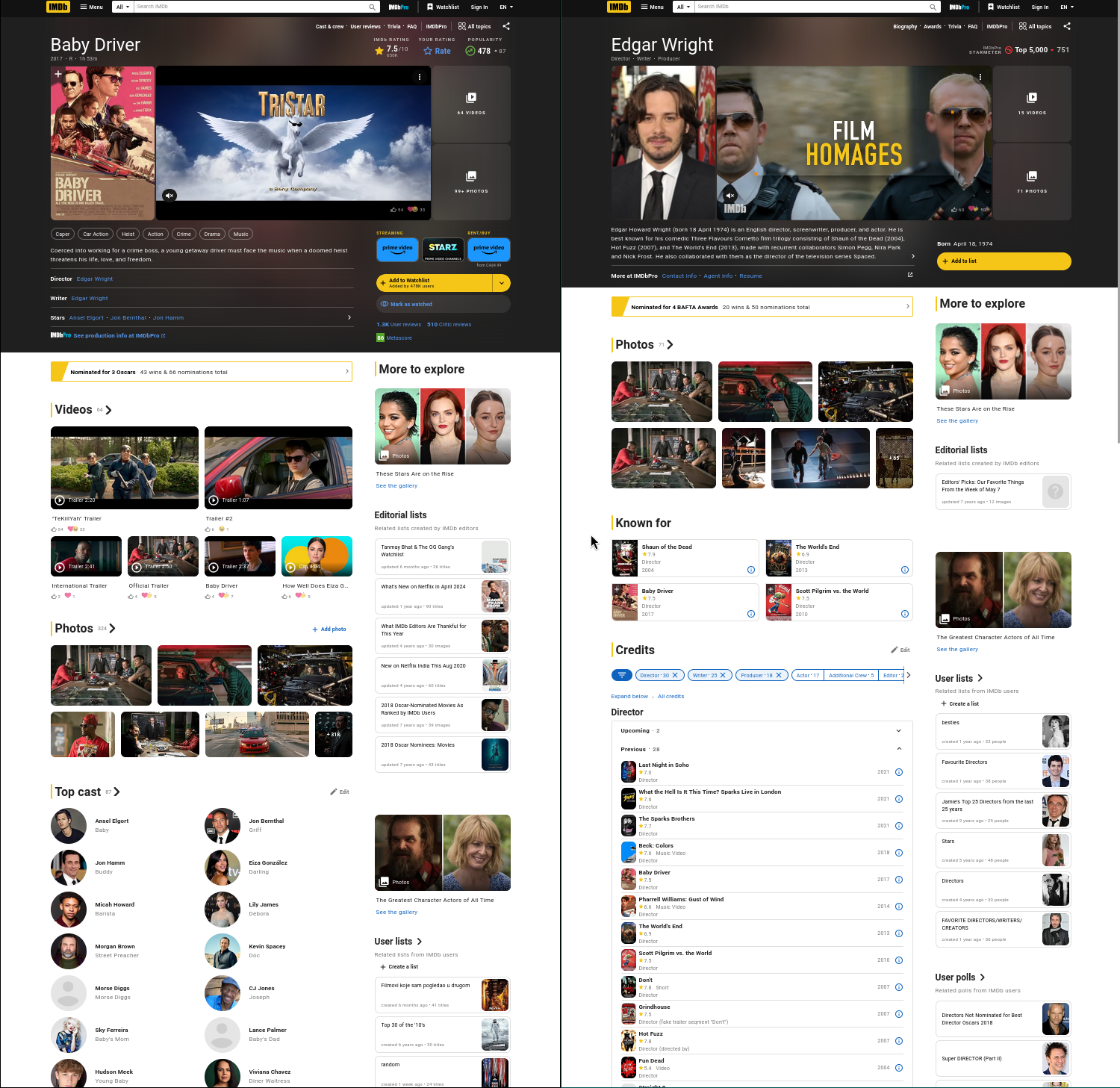
There are two things to note about these pages.
-
The data on the page is presented in a hierarchichal structure. The movie page contains a director, a list of genres, a list of actors, and each actor in the list contains a list of characters they played in the movie. You can't sensibly fit all of this into a single flat structure like a relation.
-
The order of the hierarchy isn't the same on both pages. On one page we have movie->actors and on the other page we have actor->movies. So you can't just directly store the hierarchy in your database - you need to be able to traverse relationships in both directions.
So we store all our data in a relational database in flat tables and then whenever we need to render some UI we transform the flat data into whatever hierarchy we need.
Doing this transformation by hand is tedious and error-prone. We call this tedium "the object-relational mismatch" but it isn't really about objects or relations. The fundamental problem is that fitting complex relationships to human vision usually requires constructing some visual hierarchy, but different tasks require different hierarchies.
Whatever database and programming language you use, you will have to deal with this. But it's particularly painful in sql because sql wasn't designed to produce hierarchical data.
sql wasn't built to yield structure
Let's grab the imdb public dataset and try to reproduce the source data for that movie page (or at least a subset of it, because I didn't bother importing all the tables). We want to see an output that looks like this:
{
"title": "Baby Driver",
"director": ["Edgar Wright"],
"writer": ["Edgar Wright"]
"genres": ["Action", "Crime", "Drama"],
"actors": [
{"name": "Ansel Elgort", "characters": ["Baby"]},
{"name": "Jon Bernthal", "characters": ["Griff"]},
{"name": "Jon Hamm", "characters": ["Buddy"]},
{"name": "Eiza González", "characters": ["Darling"]},
{"name": "Micah Howard", "characters": ["Barista"]},
{"name": "Lily James", "characters": ["Debora"]},
{"name": "Morgan Brown", "characters": ["Street Preacher"]},
{"name": "Kevin Spacey", "characters": ["Doc"]},
{"name": "Morse Diggs", "characters": ["Morse Diggs"]},
{"name": "CJ Jones", "characters": ["Joseph"]}
],
}
Let's grab the title first:
postgres=# select primaryTitle from title where tconst = 'tt3890160';
primarytitle
--------------
Baby Driver
And now we need the director:
postgres=# select primaryTitle, person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'director';
primarytitle | primaryname
--------------+--------------
Baby Driver | Edgar Wright
And the writer:
postgres=# select
primaryTitle,
director.primaryName as director,
writer.primaryName as writer
from title,
principal as principal_director, person as director,
principal as principal_writer, person as writer
where title.tconst = 'tt3890160'
and title.tconst = principal_director.tconst
and principal_director.nconst = director.nconst
and principal_director.category = 'director'
and title.tconst = principal_writer.tconst
and principal_writer.nconst = writer.nconst
and principal_writer.category = 'writer';
primarytitle | director | writer
--------------+--------------+--------------
Baby Driver | Edgar Wright | Edgar Wright
We're already in trouble. If this movie had 2 directors and 2 writers, this query would return 4 rows:
primarytitle | director | writer
--------------+--------------+--------------
Baby Driver | Edgar Wright | Edgar Wright
Baby Driver | Edgar Wright | A. Writer
Baby Driver | A. Director | Edgar Wright
Baby Driver | A. Director | A. Writer
If there was no director in the database then this query would return 0 rows, no matter how many writers there were. Now we don't even know what the movie is called.
primarytitle | director | writer
--------------+--------------+--------------
We can't sensibly fit the data we want into a single relation, and we can't return more than one relation per query. So we have to issue multiple queries:
postgres=# select primaryTitle from title where tconst = 'tt3890160';
primarytitle
--------------
Baby Driver
postgres=# select person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'director';
primaryname
--------------
Edgar Wright
postgres=# select person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'writer';
primaryname
--------------
Edgar Wright
postgres=# select person.nconst, person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'actor'
limit 10;
nconst | primaryname
-----------+---------------
nm5052065 | Ansel Elgort
nm1256532 | Jon Bernthal
nm0358316 | Jon Hamm
nm2555462 | Eiza González
nm8328714 | Micah Howard
nm4141252 | Lily James
nm3231814 | Morgan Brown
nm0000228 | Kevin Spacey
nm1065096 | Morse Diggs
nm1471085 | CJ Jones
postgres=# select principal_character.nconst, principal_character.character
from title, principal, principal_character
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'actor'
and principal_character.tconst = principal.tconst
and principal_character.nconst = principal.nconst;
nconst | character
-----------+---------------------
nm5052065 | Baby
nm8328714 | Barista
nm0358316 | Buddy
nm2555462 | Darling
nm4141252 | Debora
nm0000228 | Doc
nm1256532 | Griff
nm1471085 | Joseph
nm1065096 | Morse Diggs
nm3231814 | Street Preacher
Through the magic of joins we have retrieved all the data we need and it only required holding a transaction open for 4 network roundtrips.
All that's left to do now is... the same joins, but inside the backend web server. Because we have to re-assemble these flat outputs into the structure of the page.
Also note that fully half of the data returned is the nconst column which we didn't even want in the output. We only returned it because we need it as a key so we can repeat the joins that we already did in the database. The more paths you traverse, the more useless join keys you need to send to the backend web server.
All of this is pretty tedious so we invented ORMs to automate it. But:
- Almost all ORMs end up sending multiple queries for the output that we want. If you have a good ORM and you use it carefully it'll send one query per path in the output, like the raw sql above. If you're less careful you might get one query per actor in the film.
- Many ORMs also make a mess of consistency by lazily loading data in separate transactions. So we might generate a page where different parts of the data come from different points in time, which is confusing for users.
- Using an ORM locks you into only using one specific programming language. What if you need to query your data from a different language? You'll probably end up talking to the same ORM through a microservice.
old dogs can sort of learn new tricks
These days sql actually can produce structured data from queries.
A lot of people are mad about this. Whenever I talk about it they reflexively yell things like "structured data doesn't belong in the database" as if there was a universal system of morality that uniquely determined the locations of various data processing tasks.
But I can't help but note again that the structure has to happen somewhere because that's what the output page looks like and that doing it outside the database isn't working very well.
Whenever we're building a UI for humans, whether on the web or native, the main use of the query language is to turn relational data into structured data for the client to render. So it would be really nice if the query language was actually able to produce structured data.
Like this:
select jsonb_agg(result) from (
select
primaryTitle as title,
genres,
(
select jsonb_agg(actor) from (
select
(select primaryName from person where person.nconst = principal.nconst) as name,
(
select jsonb_agg(character)
from principal_character
where principal_character.tconst = principal.tconst
and principal_character.nconst = principal.nconst
) as characters
from principal
where principal.tconst = title.tconst
and category = 'actor'
order by ordering
limit 10
) as actor
) as actors,
(
select jsonb_agg(primaryName)
from principal, person
where principal.tconst = title.tconst
and person.nconst = principal.nconst
and category = 'director'
) as director,
(
select jsonb_agg(primaryName)
from principal, person
where principal.tconst = title.tconst
and person.nconst = principal.nconst
and category = 'writer'
) as writer
from title
where tconst = $1
) as result;
It's not perfect. You can definitely see the duct tape, and the query plan often suffers from the lack of decorrelation. But we can grab all the data needed for the entire page in a single query, with one network roundtrip. Whether you use these features directly or as the output of your ORM, this is a sizable improvement for one of the main usecases of relational databases!
It doesn't matter that this isn't the way things have always worked. Sql is not relational algebra and relational algebra is not math, and neither were carved into stone tablets handed down from Codd.
We make tools to serve our purposes, and our purposes have changed a hell of a lot since the 70s, when the main client of a database was a human typing sql character by character into an interactive transaction on a teletype connected to a mainframe with 500kb of RAM, almost 20 years before the invention of the world wide web. Maybe it's ok for our tools to evolve to meet new demands.