(This is part of a series on the design of zest. See the list of posts here.)
Some assorted musings on how data is represented in programming systems, with no clear thesis.
Mostly focused on how application-level data is represented, manipulated, viewed, stored and transmitted, as opposed to how new types and data-structures are implemented within a single language.
Also not an essay promoting clojure - I just use clojure for a lot of the examples because it's the only language I'm familiar with that gave deliberate thought to their data notation.
Notation
let room_occupants = HashMap::<_,_>::from_iter([
(42u64, vec!["Alice".to_string(), "Bob".to_string()]),
(43u64, vec!["Eve".to_string()]),
]);
println!("{:?}", room_occupants);
// {43: ["Eve"], 42: ["Alice", "Bob"]}
When I write this rust code I have to think about:
- The code that I write to create and change the data.
- The in-memory representation that I use to think about how code executes (some kind of vague box-and-arrows diagram in my head).
- The printed representation that appears in my logs and debug statements.
Even though the data model is the same in all three cases, I have to deal with three totally different notations for describing that data. (And to make matters worse, I don't have a parser for two of those notations.)
Here is the equivalent code in clojure:
user=> (def room-occupants {42 ["Alice" "Bob"], 43 ["Eve"]})
#'user/room-occupants
user=> room-occupants
{42 ["Alice" "Bob"], 43 ["Eve"]}
user=> (pr-str room-occupants)
"{42 [\"Alice\" \"Bob\"], 43 [\"Eve\"]}"
user=> (clojure.edn/read-string (pr-str room-occupants))
{42 ["Alice" "Bob"], 43 ["Eve"]}
In clojure the code that I write to express the data-structure is exactly the same as the printed representation. The Extensible Data Notation (edn) is a subset of clojure, in the same way the the Javascript Object Notation (json) is a subset of javascript.
This is nice when I want to eg copy a value from the repl into my code. Or copy some big data-structure from my logs into my repl so I can inspect it programmatically instead of scrolling back and forth. But that's a small benefit.
The bigger benefit is this: When I write code in most languages the mental representation that I use for thinking about data in memory is a murky sort-of-boxes-and-arrows thing. When I write code in clojure my mental representation is literally just the data literal syntax.
I think this is analogous to the oft-commented symbolic mechanization of mathematics. When I solve math problems in my head I usually don't think about the values themselves and their relationships. Instead I mentally picture some algebra expressions and then I move those expressions around in my head. By mapping complex problems into a notation that is friendly to my mental visual/spatial abilities I'm able to solve much more complex problems than if I had to think about the problem directly.
By having a carefully designed notation for data and using it consistently everywhere, I think that clojure is attempting to do something similar for data modelling. They embedded a lot of good defaults into the design of the notation, they teach the programmer a small set of primitives for manipulating that notation and then they use that notation pervasively.
Javascript/json did something similar by accident and I think it explains much of the success of json. But javascript is much less consistent in its notation eg:
var room_occupants = {
42: ["Alice", "Bob"],
43: ["Eve"],
};
console.log(room_occupants);
// { '42': [ 'Alice', 'Bob' ], '43': [ 'Eve' ] }
// so close - but why are our keys strings?!
// javascript has real data-structures now!
var room_occupants = new Map([
[42, [ 'Alice', 'Bob' ]],
[43, [ 'Eve' ]],
]);
console.log(room_occupants);
// Map(2) { 42 => [ 'Alice', 'Bob' ], 43 => [ 'Eve' ] }
// not valid javascript syntax!
console.log(room_occupants.toString())
// '[object Map]'
console.log(JSON.stringify(room_occupants))
// {}
Funnily enough, rust's serde is often better at this than javascript and is my goto for println debugging or logging in rust.
Notation elsewhere
Data notations show up all over the place - pretty much any time a human is involved in generating, transforming, inspecting or debugging data we need some kind of notation for them to interact with.
In the database...
jamie=# insert into room_occupants values (42, 'Alice'), (42, 'Bob'), (43, 'Eve');
INSERT 0 3
jamie=# select * from room_occupants;
room | occupant_name
------+---------------
42 | Alice
42 | Bob
43 | Eve
(3 rows)
On the wire...
println!("{}", serde_json::to_string(&room_occupants).unwrap());
// {"43":["Eve"],"42":["Alice","Bob"]}
In debuggers...
> rust-gdb target/debug/test-rs -ex 'catch syscall write' -ex 'run' -ex 'f 15'
Catchpoint 1 (call to syscall write), 0x00007ffff7f9bea3 in __libc_write (fd=1, buf=0x5555555bf500, nbytes=36) at ../sysdeps/unix/sysv/linux/write.c:26
26 ../sysdeps/unix/sysv/linux/write.c: No such file or directory.
#15 0x0000555555567b7b in test_rs::main () at src/main.rs:9
9 println!("{}", serde_json::to_string(&room_occupants).unwrap());
(gdb) p room_occupants
$1 = HashMap(size=2) = {[43] = Vec(size=1) = {"Eve"}, [42] = Vec(size=2) = {"Alice", "Bob"}}
In configuration...
[room_occupants]
42 = [ "Alice", "Bob" ]
43 = [ 'Eve' ]
On the whiteboard...
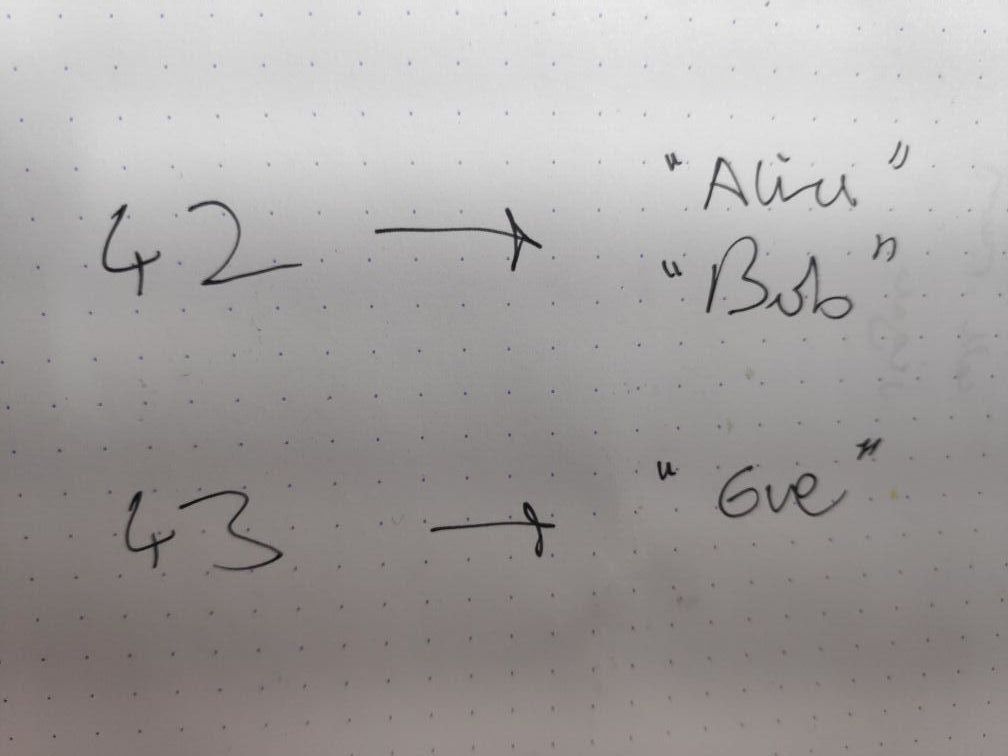
Even if the data in question is in some compact binary encoding, we still generally want to look at it using a human-friendly notation:
Having to mentally map back and forth between all these different ways to describe the same data is a waste of limited mental capacity.
I suspect that a large part of the reason for the recent popularity of key-value document databases is that it allows programmers working in OOP languages to use a familiar data model and notation for their stored data.
Read-Print-Loop
The most basic requirement for a good notation is easily converting back and forth between the in-memory representation of data and the textual representation of data. (There has to be a textual representation, otherwise how am I going to paste my problems into stackoverflow?)
In clojure for most of the core types we have this roundtrip property:
(assert (= x (clojure.edn/read-string (pr-str x))))
It's this roundtrip property that makes the textual representation an effective proxy for thinking about the in-memory representation. Without the roundtrip property you need two different mental models - one for text and one for in-memory.
It's really important that the function that maps the textual representation to the in-memory representation is read and not eval, because that means that we can use this notation to exchange data with untrusted machines who might send us "fireTheMissiles()" instead of actual data. (Javascript eventually got this right by providing JSON.parse.)
But it's also really valuable that in clojure eval is an extension of read. It means that the notation for describing data inside code is the same as the notation for describing data everywhere else.
Systems data models
I started with an example from rust and that was maybe unfair. In a typical rust program there are at least four layers of data models:
- The machine level - memory is an array of bytes behind a stack of caches
- The (unsafe) language level - memory is a graph of pointers to arrays of bytes (which are not actually bytes)?
- The (safe) language level - memory is a graph of owned or borrowed references to typed memory locations. Except when it contains some other abstraction implemented in the unsafe level?
- The application level - data is a pile of hashmaps and arrays full of structs and strings
When I'm working at the machine level everything is just a list of numbers. Notation is easy.
When I'm working at the application level I can get away with printing everything to json or similar. Maybe if I'm feeling fancy I'll add a cycle detector so printing can't blow up.
But the language level is complicated. I don't even really know what the data model is. I read things like pointers are not integers and memory is not bytes and the idea of provenance makes sense, but I don't know how to write it down. A notation that captures the whole complexity of this level would be a serious endeavour.
Even just printing things at the language level is hard without cooperation. I can't just print out the data table of the hashmap because I don't know which slots contain invalid uninitialized values. That information is recorded elsewhere.
So notation for the language level is hard. But I don't think that prevents systems languages having a strong data notation at the application level.
Zig is perhaps in a good position to try this because of the way it constructs data. Rather than having a syntax for creating eg a struct or enum directly, there is a syntax for creating anonymous literals and a list of rules for implicitly coercing literals into other types.
const MyStruct = struct {
x: u8,
y: u64,
};
const MyEnum = union(enum) {
Foo: usize,
Bar: MyStruct,
};
const anon = .{ .Bar = .{ .x = 0, .y = 1000 } };
const typed: MyEnum = anon;
std.debug.print("{}\n", .{@TypeOf(anon)});
// struct:16:19
std.debug.print("{}\n", .{@TypeOf(typed)});
// MyEnum
std.debug.print("{}\n", .{anon});
// struct:16:19{ .Bar = struct:16:29{ .x = 0, .y = 1000 } }
std.debug.print("{}\n", .{typed});
// MyEnum{ .Bar = MyStruct{ .x = 0, .y = 1000 } }
This nicely demonstrates the separation of encoding and notation: Anonymous literals provide a generic data notation but we can still control the encoding in memory by coercing the literal to a type with a well-defined layout, similarly to how postgres uses strings for all data literals but determines encodings from the column type - select cast('2021-03-11' as date).
That separatation means that something like this should be possible:
const room_occupants = try zdn.read(
allocator,
HashMap(u64, ArrayList(String)),
\\ .{
\\ .{42, .{"Alice", "Bob"}},
\\ .{43, .{"Eve"}},
\\ }
,
);
zdn.print(room_occupants);
// .{
// .{42, .{"Alice", "Bob"}},
// .{43, .{"Eve"}},
// }
const room_occupants2 = try zdn.read(
allocator,
HashMap(u64, ArrayList(String)),
try zdn.printToString(allocator, room_occupants),
);
assertEqual(room_occupants, room_occupants2);
The main obstacles to even tighter mapping are that there is no global namespace and no global allocator. So we could have toZdnString produce "HashMap(u64, ArrayList(String)).fromZdn(allocator, ...)" but you could only paste that code into a namespace where HashMap and ArrayList were already imported and allocator was bound.
This is unlikely to change in zig. But I can imagine a systems language with java-style globally unique namespaces and clojure-style dynamic variables that could achieve a tight read-print-loop. (Roc also seems to be in a position to do something like this with it's structural types).
Getting the same behavior in a debugger is harder. Perhaps we could:
- analyze a program
- list all the types that are used
- emit a printing function that takes a type id and an untyped pointer
- include the type ids of each variable in the dwarf info
- hook up gdb/lldb to look up the type id and call the printing function
But this probably wouldn't be as simple as it sounds because everything that dwarf touches is riddled with bitterness.
Mapping data to behavior
There is a more subtle benefit to having read be separate from eval, which is that we can work with the data independent of the programming language that created it.
Json took over the world because it is language independent but also a reasonable subset of the average dynamic object-oriented language, so it makes for a familiar notation.
One thing that json does poorly though is dealing with types:
> x = new Date(Date.now())
2022-03-09T21:08:34.243Z
> x.getMonth()
2
> y = JSON.parse(JSON.stringify(x))
'2022-03-09T21:08:34.243Z'
> y.getMonth()
Uncaught TypeError: y.getMonth is not a function
At first the desire to make the above code work seems like a contradiction - how can the methods attached to an object be serialized in a language independent way? But we can separate this into two goals:
- Communicate in the notation that some piece of data should be interpreted in a particular way (eg as a date.)
- On reading the data, associate the in-memory representation with some language-specific bundle of behavior (ie the
Dateclass).
In clojure, goal 1 is achieved by tagged elements:
user=> (def x #inst "1985-04-12T23:20:50.52Z")
#'user/x
user=> x
#inst "1985-04-12T23:20:50.520-00:00"
user=> (type x)
java.util.Date
user=> (pr-str x)
"#inst \"1985-04-12T23:20:50.520-00:00\""
user=> (def y (clojure.edn/read-string (pr-str x)))
#'user/y
user=> y
#inst "1985-04-12T23:20:50.520-00:00"
user=> (type y)
java.util.Date
user=> (= x y)
true
user=> (.getMonth y)
3
Goal 2 is achieved by providing read with a mapping between tags and types. Above we used the inst tag which is mapped to java.util.Date by default. But we could define our own mapping instead:
user=> (defrecord MyInst [time-str])
user.MyInst
user=> (def z (clojure.edn/read-string {:readers {'inst ->MyInst}} (pr-str x)))
#'user/z
user=> z
#user.MyInst{:time-str "1985-04-12T23:20:50.520-00:00"}
user=> (defmethod print-method MyInst [inst writer]
(doto writer
(.write "#inst ")
(.write (pr-str (:time-str inst)))))
#object[clojure.lang.MultiFn 0x504e1599 "clojure.lang.MultiFn@504e1599"]
user=> z
#inst "1985-04-12T23:20:50.520-00:00"
We can also define a default mapping for tags we don't recognize:
user=> (defrecord Tagged [tag thing])
user.Tagged
user=> (clojure.edn/read-string {:default ->Tagged} "[#foo 1 #bar 2]")
[#user.Tagged{:tag foo, :thing 1} #user.Tagged{:tag bar, :thing 2}]
This separation of tags and types allows the data notation to be both self-describing and extensible - goals which at first seem impossible to reconcile.
A similar separation appears in postgres:
postgres> create table example(d date, i interval, t text, j jsonb);
CREATE TABLE
postgres> insert into example values ('2021-09-30', '2 months ago', 'hello world', '{"a": 1, "b": 1}');
postgres> select * from example;
d | i | t | j
------------+---------+-------------+------------------
2021-09-30 | -2 mons | hello world | {"a": 1, "b": 1}
(1 row)
Postgres defines conversions from/to text for every type. Even though each type is stored internally using a specific encoding, the syntax and the default wire protocol both use only the text representation. This means that when postgres adds a new type, existing tools and clients continue to work transparently but newer versions of clients can opt-in to richer non-text representations.
Layering
Clojure layer types over tags over edn over raw text. This layering makes the notation robust. If you go all the way up to the type layer you can get very rich behavior associated with each item of data. But unfamiliar tags can still be read into some default representation and the data can still be sent, viewed and manipulated in any system that understands raw text.
We can do similar layerings on other axes.
Chrome's html inspector shows the benefits of layering a structured gui over a textual notation, as opposed to just using one or the other.
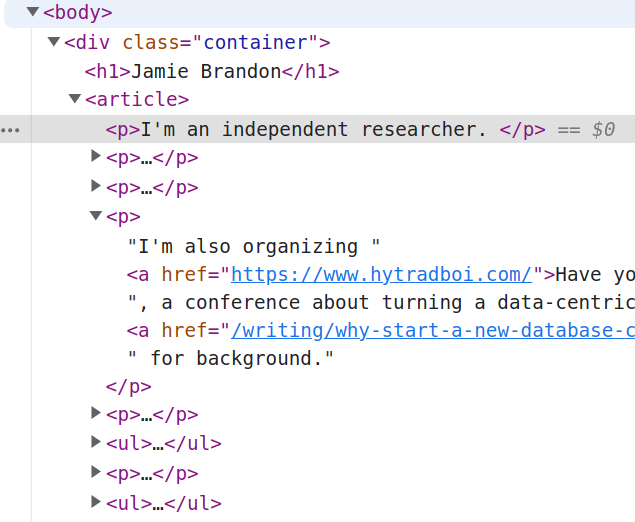
It's much easier to navigate and understand the structure of a large html document in this expandable tree gui than in plain text. Each node is also augmented with useful commands like 'scroll into view'.
Individual edits are easily made by double-clicking directly on the node or attribute I want to edit. But for bulk edits it's usually easier to flip part of the tree back into text.
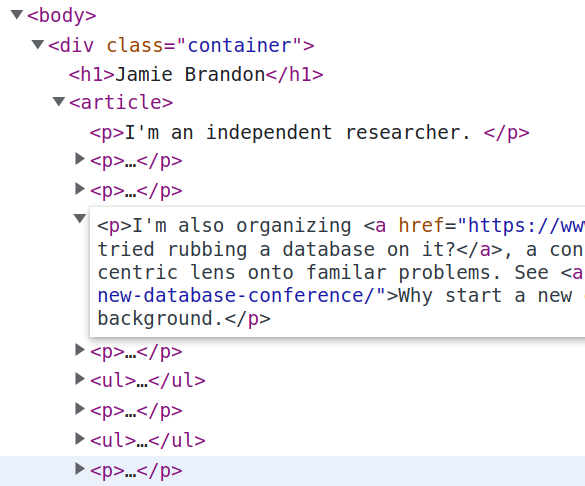
This seems like a promising approach to structured editing in general - focus the gui on handling operations that mostly preserve structure and fall back to a less structured layer for larger changes.
This approach also allows the gui to preserve one really key property of text: I can take a screenshot of code in any textual language and instantly know how to reproduce the same program in my editor, because there is a one-to-one mapping between the characters on the screen and the keys on my keyboard.
In many graphical programming languages, by contrast, it's not obvious by looking at the code what actions you would have to take to reproduce it. This makes it harder to learn by looking at existing code.
Pointers vs ids
The chrome console uses a similar ui to the html inspector, but can't flip parts of it back to text.

This is likely because the textual representation isn't capable of capturing all the features of the language. For example, json arrays have their own dedicated notation but in javascript arrays are also objects and can be assigned properties that don't fit in the array notation.
> x = ['a', 'b', 'c']
[ 'a', 'b', 'c' ]
> x.foo = 42
42
> x
[ 'a', 'b', 'c', foo: 42 ]
> JSON.stringify(x)
'["a","b","c"]'
Javascript objects can also contain aliased pointers or cycles, but json has no way of talking about pointers.
> x = []
[]
> x[0] = x
<ref *1> [ [Circular *1] ]
> JSON.stringify(x)
Uncaught TypeError: Converting circular structure to JSON
--> starting at object with constructor 'Array'
--- index 0 closes the circle
at JSON.stringify (<anonymous>)
In clojure all the core data-structures are immutable. It's not possible to create a cycle in the pointer graph so the data notation doesn't have to worry about how to represent pointers.
That might seem like a heavy limitation, but in other contexts it's one that people take on voluntarily. In rust, people default towards modelling data with owned data-structures and ids to avoid having to deal with lifetime annotations everywhere. In game development, there's a movement away from object graphs and towards using ids to link data. And we've been modelling data with ids in relational databases since the 70s.
(See also Handles are the better pointers).
But what is the difference between modelling a graph using pointers and modelling a graph using ids? They are both just numbers that tell us where to find linked data. But:
- A pointer is an id that can only be associated with one value. This makes it harder to compose data from multiple sources without cooperation between them, or make multiple different versions of some collection of data.
- A pointer is a capability - any code that can read the pointer can also read or write the associated value.
- Pointers are non-portable. An id is the same on any system, but sending a pointer graph of the wire requires remapping pointers or messing with virtual memory mappings. This makes it much harder to move data around and convert it between different representations.
- Pointers are non-deterministic. Running the same program multiple times will often produce different pointers (eg because of ASLR).
- When using a moving garbage collector, pointers are not stable. The location of an object could change at any time and only pointers that are within the scope of the gc will be fixed up. This means that there is no way to store or share a stable reference to this object outside the current runtime.
Another way to think about it is that a pointer combines an id with the context for interpreting that id. The id 42 is just a number, but the pointer 42 is something we can dereference to find out what it refers to.
At some point we have to interpret ids, so we have to have pointers or something like them for providing context. But there are hefty advantages to restricting our application-level data model to be a tree and using ids to model the graph-like parts.
Ids vs names
We could removed nested structure entirely and link everything via ids, as in 6nf.
One problem with this approach is that the textual version of the data notation becomes very hard to read and write. It requires holding many ids in short-term memory. Also related data is typically not close together in the text, so looking up ids involves repeatedly scanning the text and maybe scrolling back and forth.
It's pretty easy to improve this in a gui representation. For example, in airtable the underlying ids are never shown. Instead each is associated with a meaningful name.

The names also act as links - double-clicking on a name brings up the underlying record.
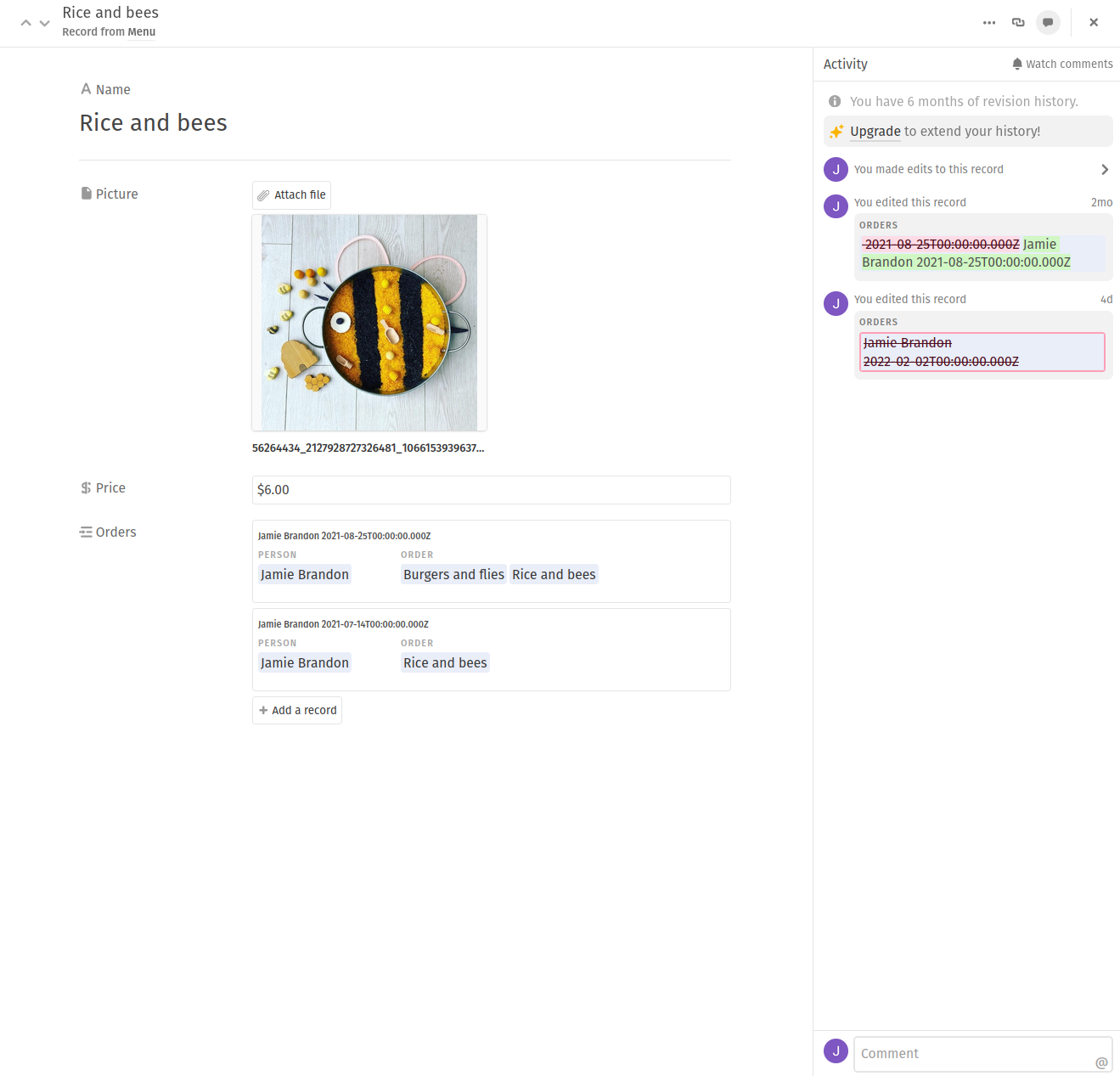
This navigates a tricky tradeoff: It's much easier for humans to remember meaningful names than random ids. But it's really useful to be able to change names without breaking existing references.
How could we bring this to a general textual notation? If I export this part of the table to csv I get:
Person,Date,Order
Jamie Brandon,8/25/2021,"Burgers and flies,Rice and bees"
Jamie Brandon,7/14/2021,Rice and bees
Jamie Brandon,8/25/2021,Burgers and flies
Jamie Brandon,2/2/2022,"Burgers and flies,Rice and bees"
Only the names are shown, but airtable doesn't require names to be unique.

Using names is also not ideal as a notation for communicating between sites or storing over time - if I send this data to a system where the name for some id has since been changed then this data can no longer be interpreted.
If I hit the rest api instead, I only get ids for records nested in 'Person' and 'Order':
[
{
"id":"rect2UPCb5RhQm9eH",
"fields":{
"Date":"2021-08-25",
"Person":[
"recLag8JVDw9y7cwj"
],
"Order":[
"recsxjMS4j4apNJey",
"reczqWPZyzfXB27pk"
],
},
"createdTime":"2021-08-25T18:03:45.000Z"
},
...
]
This is perfectly fine as a notation for machines but is hard for humans to read and debug.
How could we design a notation that use stable references but is also easy to read?
The problem of choosing between meaningful name and stable reference isn't limited to data. In almost every programming language we refer to functions by name. Refactoring tools make it trivial to change the name of a function within a single organization, but coordinating changes to names across multiple organizations is still painful.
Unison attacks this problem by referring to functions by globally unique ids. To make it possible for humans to write code, the compiler allows writing code using names but maps those names to ids internally. If the programmer uses a name which is ambiguous, it can be disambiguated using the syntax name#id.
If we apply a similar approach to our Orders table from above, we could type out the data by hand like this:
[
{
:person "Jamie Brandon"
:date "8/25/2021"
:order [
"Burgers and flies"
"Rice and bees"
]
}
...
]
If we're just interacting with a local system for a short time then this notation is fine. But if we want to send the data elsewhere or store it for later, the ide autocomplete or some batch tool could fill in the ids:
[
{
:person "Jamie Brandon"#recLag8JVDw9y7cwj
:date "8/25/2021"
:order [
"Burgers and flies"#recsxjMS4j4apNJey
"Rice and bees"#reczqWPZyzfXB27pk
]
}
...
]
Any system reading this can use the ids as stable references, and can choose whether to issue a warning or error if the name associated with that id has changed.
Shorthand
The conversion from name to name#id is an example of how shorthand notations can make text notations more usable.
Another example of a shorthand occurs in clojure's namespaced keywords. Namespaced keywords allow creating globally unique names, so that you can mix data from different sources without name collisions.
user=> (= :foo :net.scattered-thoughts/foo)
false
Typing full namespaces all the time is a pain though, so there are several shorthands.
The shorthand :: always expands to the current namespace.
user=> ::foo
:user/foo
Other namespaces can be assigned shorthands by using alias.
user=> (alias 'me 'net.scattered-thoughts)
nil
user=> ::me/foo
:net.scattered-thoughts/foo
Each of these examples of shorthand works by exploiting some local context. For unison the context is the local codebase, for clojure the context is the current namespace, and for the database notation the context is the current mapping from ids to names.
Exploiting the context allows having a compact and readable notation, while still being able to expand to something globally interpretable when communicating between different contexts.
Scope
We've talked about a lot of features that json doesn't provide, like non-string keys in maps, extensible types, name#id pairs. Why do these need to be explicitly support by the data notation rather than just using some convention to encode them?
For example, we could represent maps using arrays of key-value pairs:
[
[42, ["Alice", "Bob"]],
[43, ["Eve"]],
]
In cases where our code knows that types to expect this works fine. But when we're trying to process data that we don't know the type of in advance, the fact that the data notation doesn't convey how this map is supposed to be interpreted makes for a much worse development experience. It won't be mapped to an associative data-structure in memory. GUI inspectors won't know that they should render keys and values separately. We don't know if the order matters, or if we're allowed to have two key-value pairs with the same key. Etc.
But we can't cram every possible property of the data into the data notation or it will become a programming language. So the game is to try to ensure that the most important properties can be expressed precisely, concisely and readably.
Changing data
The data model specifies what kinds of changes are allowed. For a sql database, the changes might be inserts and deletes of rows from existing tables. For a typical imperative language, the change model is more complicated - something along the lines of 'replacing the contents of some variable or memory location with another value of the same type'.
It's often useful to be able to represent the changes themselves as data. For example if we want to talk about the diff between two datasets or store an undo log or synchronize changes between sites (cf automerge, the truth).
In a tree-shaped data model like json or edn this is easy. We can represent locations by paths and describe all changes with a small set of operations on paths.
user=>
(def state (atom {
:rooms #{42 43}
:room-occupants {42 #{"Alice" "Bob"}, 43 #{"Eve"}}
}))
#'user/state
user=>
(def changes [
[[:rooms] :conj 44]
[[:room-occupants] :assoc 44 #{"James"}]
[[:room-occupants 43] :disj "Eve"]
])
#'user/changes
user=>
(doseq [[path op & args] changes
:let [f (case op :assoc assoc :dissoc dissoc :conj conj :disj disj)]]
(apply swap! state update-in path f args))
nil
user=> @state
{:rooms #{43 44 42}, :room-occupants {42 #{"Alice" "Bob"}, 43 #{}, 44 #{"James"}}}
This is trivial in most data models. But there are two common ways it can go wrong.
The first way is if the program has some state that isn't accessible from the global scope by any stable/representable path. I run into this a lot in javascript, where it's idiomatic to represent local state by capturing it in a closure. And then the closure itself might only be reachable from some queue in the event loop which can't be accessed from the language itself.
> function counter() {
... var count = 0
... function countOutLoud() {
..... console.log(count);
..... count += 1;
..... setTimeout(countOutLoud, 1000);
..... }
... countOutLoud();
... }
undefined
> counter()
undefined
0
1
2
3
4
...
Good luck serializing that state. It's also a problem if you want to live reload code during development, because the countOutLoud closure won't get reloaded.
I think it's notable that react uses hooks to provide the illusion of having this style of local state, but actually stores all the hook values in a single data-structure.
The second way that reifying changes as values can go wrong is if the data model is too anaemic to represent arbitrary paths/data. For example, here is the same example in sql:
postgres> insert into rooms values (44);
INSERT 0 1
postgres> insert into room_occupants values (44, 'James');
INSERT 0 1
postgres> delete from room_occupants values (43, 'Eve');
DELETE 1
Just kidding, you can't delete a list of values:
postgres> delete from room_occupants values (43, 'Eve');
ERROR: syntax error at or near "("
LINE 1: delete from room_occupants values (43, 'Eve');
postgres> delete from room_occupants where room = 43 and occupant_name = 'Eve';
DELETE 1
SQL shade aside, how could we represent these changes as data?
postgres> values
('rooms', +1, 44),
('room_occupants', +1, 44, 'James'),
('room_occupants', -1, 43, 'Eve');
ERROR: VALUES lists must all be the same length
LINE 3: ('room_occupants', +1, 44, 'James'),
Right, right, no mixed-arity relations. Also no sum types or union types.
We could make a separate relation for changes to rooms and to room_occupants. But there is no way to return multiple expressions.
postgres> with
rooms_changes as values (+1, 44),
rooms_occupants_changes as values (+1, 44, 'James'), (-1, 43, 'Eve')
...what can we put here?...
So we'll have to make global tables:
postgres> create table rooms_changes(diff integer, room integer);
CREATE TABLE
postgres> create table room_occupants_changes(diff integer, room integer, occupant_name text);
CREATE TABLE
postgres> insert into rooms_changes values (+1, 44);
INSERT 0 1
postgres> insert into room_occupants_changes values (+1, 44, 'James'), (-1, 43, 'Eve');
INSERT 0 2
Then if we want to execute these changes we have to hand-write DDL for each table:
postgres> insert into room_occupants (
select room, occupant_name
from room_occupants_changes
where room_occupants_changes.diff = 1
);
INSERT 0 1
postgres> delete from room_occupants where exists (
select * from room_occupants_changes
where room_occupants.room = room_occupants_changes.room
and room_occupants.occupant_name = room_occupants_changes.occupant_name
and room_occupants_changes.diff = -1
);
DELETE 1
Not fun. In practice, we'd probably just store the changes in one table as json and then use some less anaemic language to generate this DDL on the fly.
In imp this example is much easier because the language supports higher-order functions and heterogenous sets.
with_changes: ?@state ?@changes (state | (changes :insert)) -- (changes :delete);
state:
| :rooms, (42 | 43)
| :room_occupants, (42, ("Alice" | "Bob") | 43, "Eve");
changes:
| :insert, :rooms, 44
| :insert, :room_occupants, 44, "James"
| :delete, :room_occupants, 43, "Eve";
new_state: state@ with_changes changes@;
Code is data
Many dynamic languages have an eval function which takes a string containing some code and evaluates it.
The idea behind the phrase 'code is data' is to separate this into two functions: a read function which takes a string containing some code and returns a data-structure describing some code, and an eval function which takes that data-structure and evaluates it. Having this intermediate step where the code is represented by some data-structure instead of a string makes it much easier to manipulate and analyze code.
'Homoiconic' languages like clojure take this further by ensuring that the syntax for code is almost identical to the syntax for the data-structure that describes that code. For example, these three clojure expressions are equivalent:
(eval (read "(+ a b)"))(eval '(+ a b))(+ a b)
I'm not sure how much this actually matters.
Having a small mental distance between the way code is written and the way that the data-structures describing code are written does reduce mental load when writing code analysis and transformation tools.
But combining quasiquoting and pattern-matching against quasiquotes also achieves this goal. I reach for pattern-matching even in lisps because it's easier for me to understand what kind of expression is being manipulated when reading (match expr '(def ~name ~@body) ...) than when reading (do (assert (seq? expr)) (assert (= 'def (nth expr 0))) (let [name (nth expr 1) body (drop 2 expr)] ...)). But the pattern-matching approach also works just as well in languages like julia which have quasiquoting but are not homoiconic.
There are advantages though to having a simple, regular syntax. Tools like syntax highlighters, linters, formatters, structured editors etc become much easier to write. It's also easier to learn and remember the syntax (the clojure examples in this article are the first I've written in years but I didn't have to look up the syntax or the core data manipulation functions).
The codebase is data
In clojure we can read the code in a file, but the resulting data-structure doesn't describe the namespace directly - instead it describes a sequence of imperative operations which will mutate the namespace. The only way to understand the resulting namespace is to run the code and see what happens.
(def a (+ 1 1))
; override the definition of +
(eval "(require '[bad-idea :refer [+]])")
; there is no way to analyze this definition correctly without executing the code above
(def b (+ 1 1))
This is why clojure's AOT compilation requires evaluating the codebase and then dumping the resulting bytecode. It's why the various code reloading tools come with so many caveats. It's reminiscent of the pre-react days of web development when we were all just adhoc mutating the dom and hoping to keep everything in sync by hand.
The only language I know of that takes 'the codebase is data' seriously is unison, where the codebase is a data-structure stored in a content-addressed append-only database. This enables making transactional changes to the state of the code, among other features.
A side-effect of this is that because functions are identified by stable ids rather than mutable references, you can serialize closures and send them over the wire. If the receiver has access to the same codebase it can look up the definition and call the function. But even if it doesn't have access to the same codebase it can at least still read the closure and pass it around, much like with the separation between tags and types in clojure.
Execution is data
Let's really stray off course.
Part of the reason that programming is so difficult to learn is that most of what is happening is invisible by default and can only be inspected with active effort. Even when we sprinkle code with printlns everywhere, the result is a series of random strings rather than a useful data-structure about which we can ask sensible questions, like "where did this NaN come from?".
What if we could reify the execution of a program as some native data-structure?
Pernosco records the execution of arbitrary native programs and allows asking not just simple questions like "where did this NaN come from?" but also outrageous questions like "when did this pixel on the screen change and what line of code set its color?" or "if I had thought to put a println here, what would it have printed?".
These are the kinds of questions I want to ask, but I also want to be able to ask them easily using the same language I used to write the program in the first place rather than switching to totally different system.
In restricted languages this is somewhat easier. For example in datalog I could reasonably ask for the set of variables bound in a rule (including variables not bound in the head), or the set of variables that were bound by the first N clauses.
But once a language adds iteration or over complex control flow it becomes much harder to even phrase questions. "What variable was bound in the 11th iteration of this loop when this function was called from bar the second time after the..."
The design doc for subtext 10 describes a language whose execution is homoiconic - the execution trace is an expanded version of the same data-structures that were used to define the code. It was never implemented, but it seems feasible.
Wishlist
Data model:
- A small set of primitives - so we can write generic operations over arbitrary data
- eg writing an inspector gui
- eg searching for references to some id
- But still able to represent types and invariants - extensible but self-describing
- Able to reify changes as data
- eg for undo log
- eg for real-time collaboration
- All data has some name/path/location by which it can be referred to
- eg no hidden state in closures
- eg no hidden closures in the event loop queues
- Avoid depending on pointers for identity
Data notation:
- A textual representation which is easy to read/write
- Used consistently everywhere - one standard way of picturing data
- Self-describing - doesn't require out-of-band type/schema information to interpret
- Uses layering to add capabilities while mimicking familiar notation
- eg the chrome html inspector mimics the text notation of html
- Uses shorthands and exploits context to reduce redundant information
- eg clojure namespace aliases
- eg unison names
Code:
- The notation for code is a superset of the notation for data
- eg can print data and copy-paste into code / repl
- Can choose the mapping between tags in data notation and types in code
- Code can be represented as data with low mental distance
- The codebase is also data - can trivially analyze whole thing including dependencies without having to execute side effects
- Maybe, if possible, reify the execution of code as data
Crucially, the data model and the data notation need to be co-designed, because it's so easy to make choices in the data model that prevent creating a good data notation later.