Preimp
I've made a lot of progress on preimp. Persistence, server/client sync and collaborative editing are all working. Values are nicely rendered as tables. Functions are rendered as forms, which you can fill out to call the function. Functions can call edit! to change the value of data cells. Metadata can be used to tweak the rendering of values.
Together these features allow quickly throwing together interactive apps. You just have to write the actual logic and you get (ugly) interactive ui, persistence and (coarse-grained) collaborative editing for free.
I wrote an accounting app in preimp to share with my wife. Here's a sneak peek of one of the cells:
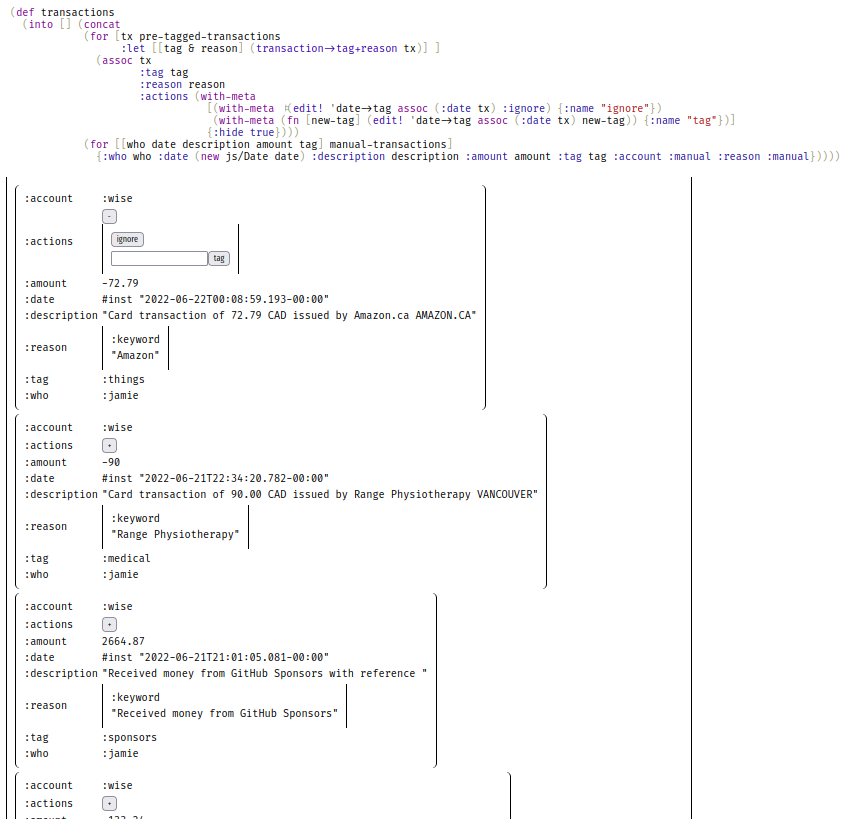
It's almost usable - I just have to figure out how to improve the rendering performance for large values. I'm seeing >1000ms frames to display <600 transactions, much of which is spent in opaque browser-land.

I also added a PUT endpoint to the server that allows setting the values of cells remotely, and wrote a little script that fetches transactions from my bank and adds them to the budgeting app:
(ns wise
(:require [clj-http.client :as client]
[clojure.data.json :as json]))
(def endpoints {
;; FILL ME IN
})
(defn api-get [user path]
(let [domain (get-in endpoints [user :wise-domain])
url (str domain "/" path)
response (client/get url {:headers {"Authorization" (str "Bearer " (get-in endpoints [user :wise-token]))}})]
(assert (= 200 (:status response)))
(json/read-str (:body response))))
(def now (java.time.Instant/now))
(defn get-transactions [user]
(into []
(for [profile (api-get user "v2/profiles")
:let [profile-id (get profile "id")]
balance (api-get user (str "v4/profiles/" profile-id "/balances?types=STANDARD"))
:let [balance-id (get balance "id")
statement (api-get user (str "/v1/profiles/" profile-id "/balance-statements/" balance-id "/statement.json?intervalStart=2022-01-01T00:00:00.000Z&intervalEnd=" now "&type=COMPACT"))]
transaction (get statement "transactions")]
transaction)))
(defn update-preimp [user]
(let [transactions (get-transactions user)
cell-name (symbol (str (name user) "-wise-transactions"))
cell-value (pr-str `(~'defs ~cell-name ~transactions))
body (json/write-str
{:cell-id (get-in endpoints [user :cell-id])
:value cell-value})]
(client/put
(get-in endpoints [user :preimp-domain])
(merge (get-in endpoints [user :preimp-headers]) {:body body}))))
(defn update-preimp-dev [_]
(update-preimp :sandbox))
(defn update-preimp-prod [_]
(update-preimp :jamie)
(update-preimp :cynthia))
I'm hoping in the next month or two to be able to turn this into an (interactive?) essay.
Focus
I added language-specific completions, although still just tokenizer-driven with no understanding of scoping. Also some minor bug fixes.
I've been eyeing up mach which aims to provide a platform for cross-compiling webgpu apps for all major platforms (including wasm).
In the process they're producing a lot of from-source bindings and build scripts for various libraries. I've already switched focus' font rendering from sdl-ttf to mach-freetype and I plan to switch from sdl to mach-glfw. That would simplify cross-platform builds already.
But I'm also considering building on top of mach.platform and webgpu (probably as a branch for now, until mach is less of a moving target). That would allow me to compile (a subset of) focus to run in the browser, making it easier to share demos like the imp live repl without having to maintain two separate implementations.
Emergent Ventures
Emergent Ventures gave me a $50k grant to work on imp.
They also recommended using some of that money to travel and meet more people. So far I'm thinking about Handmade Seattle (90%), Strange Loop (60%) and Boston (60%). I'd welcome additional suggestions for events or groups of people to visit.
Clockwork Labs
I've started working with Clockwork Labs, in the same 8-hours-per-month advisory role I have with XTDB.
I'm not sure yet about the business model, which is still in flux but has some risk of including the phrase "cryptocurrency". But the core product is interesting:
SpacetimeDB is a distributed relational database system which lets clients interact directly with the database by embedding application logic inside the database using wasm (like stored procedures, but with languages like rust/typescript/etc).
They also asked me to mention that they are hiring, especially for database engineers.
Success
In the first two years after leaving materialize I made a total of $20,171.
So it's a relief to realize that, between github sponsors, xtdb and clockwork labs, my wife and I are actually in the black this month.
On top of that, hytradboi and the emergent ventures grant gave us an 11 month runway to cover the inevitable gaps in consulting income.
So this is a real thing now. I'm actually an independent researcher, not just unemployed.
HYTRADBOI ideas
I'm still on the fence about whether I want to HYTRADBOI again in 2023. But I've been throwing around some ideas:
- Instead of soliciting talk proposals, solicit recommendations for who I should ask. You can't recommend yourself.
- Ask speakers to talk about a project that is not their own. So rather than self-promotion we'd get people explaining some idea that they think is important.
- After the conference, solicit essays / blog posts on attendees thoughts / reactions. Publish links to all the submisions below each talk.
Zig debugging tips
(Thanks to Isaac Freund)
Usually zig release builds don't emit stack traces on crashes. Compiling with -fno-omit-frame-pointer (or exe.omit_frame_pointer = false;) fixes this.
The release stack traces are still printed wrong because of an outstanding bug in the compiler but if you enable coredumps on linux (google instructions for your distro) you can coredumpctl -r debug to open the most recent crash in a debugger and see the correct trace.
dev-setup.sh
For some projects it takes me a few minutes to setup my workflow. I've been experimenting with scripting this process via the window manager:
#!/usr/bin/env bash
cd "$(dirname "$(readlink -f "$0")")"
rm -rf ./out
swaymsg workspace 0
alacritty --working-directory ./ -e nix-shell --run 'clj -M --main cljs.main --watch src --compile preimp.core' &
alacritty --working-directory ./ -e nix-shell --run 'clj -X preimp.server/-main' &
sleep 1 # :(
swaymsg workspace 1
$EDITOR ./src/preimp/core.clj &
sleep 1 # :(
swaymsg workspace 2
$EDITOR ./src/preimp/core.cljs &
$BROWSER localhost:3000 &
It's not quite right yet - when one of those processes exits it takes the others with it. But it feels like a workable idea.
Clojurescript blues
I haven't used clojurescript for a long time. I picked it for preimp because I had very specific needs for this prototype - I need a language that compiles to javascript, can run the compiler in the browser, has persistent data-structures, can roundtrip print->parse for most values, and is easy to parse. Eventually I'll have to implement all of that from scratch for imp, but in the meantime this is a nice way to test out some ideas.
But it's also been a reminder of all the reasons that I don't use clojure for other projects.
Dynamic typing and pervasive nil-punning massively increase the distance between making an error and seeing the effects, which makes debugging much more time-consuming. For example when using the self-hosted clojurescript compiler you can specify what namespace to evaluate the code in. I passed a namespace (preimp.core) instead of the symbol naming that namespace ('preimp.core). In julia this likely would have been an immediate type error - something like no method matching eval(::String, ::Namespace). But instead what happened is the compiler generated invalid javascript. Eg (fn [] edit!) compiled to (function (){\nreturn .edit_BANG_;\n}).
Debugging that mistake was made slower by the suspicion that this was a compiler bug. Because I already ran into multiple different miscompilations that week. Eg (def zzz ^{:name "add 1 to x"} (fn inc [] (edit! 'x inc))) compiled to (function (x){ return cljs.core.with_meta(return (function preimp$core$inc(){ return preimp.core.edit_BANG_.call(null,new cljs.core.Symbol(null,"x","x",(-555367584),null),preimp$core$inc);}); ,new cljs.core.PersistentArrayMap(null, 1, [new cljs.core.Keyword(null,"name","name",(1843675177)),"add 1 to x"], null));}) which is, again, invalid javascript.
At one point I tried switching from reagent to rum. It took me an hour to rewrite my ui code and two days to get it to compile. The clojurescript version I started with miscompiles rum. Older clojurescript versions worked with debug builds but failed with optimizations enabled, claiming that cljs.react was not defined despite it being listed in rum's dependencies. I eventually ended up with a combination of versions where compiling using cljs.build.api works but passing the same arguments at the command line doesn't.
Having working debug builds and failing release builds has been a common problem too. It's pretty common for clojurescript workflows to have a lot of conditional compilation to enable repl-driven workflows. Release builds also use a different toolchain and module-loading mechanism. So I often can't debug in my debug builds because the bug only appears in release builds.
For a while I had a bug where clean builds compile succesfully but incremental builds would complain about missing imports that weren't actually missing. I don't know what caused it, and I don't know why it stopped. A clean build of preimp takes 2m30s. (A clean release build of imp2 takes 60s.)
All of this is frustrating because I really would like to use clojurescript more often. The data notation is really well thought out. The datastructure manipulation functions in the core library work together beautifully (nil-punning aside). There are some solid libraries for dealing with state and ui. But none of that saves me any time in the long run because the core tooling is so poor.
Analogies for end-user programming
I've been thinking about convivial vs industrial modes of production. There are some fields where convivial production is almost completely dead eg hardly anyone builds their own cars anymore and there is little to be gained by doing so. In other fields there is a smooth continuum eg most homes are professionally built and most furniture is mass-produced, but Home Depot still exists and basic carpentry skills are still useful. (I spent a chunk of last year sleeping on a hand-made bed in the back of Honda Odyssey. You can't buy those at Ikea.)
In terms of this analogy, a lot of objections to end-user programming sound to me like arguing that Home Depot is a waste of time because their customers will never be able to build their own skyscrapers.
And then on the other side are the people arguing that people will be able to build their own skyscrapers and it will change the world.
I just think it would be nice if people had the tools to put up their own shelves if they wanted to.
Another angle on this is that industry is pretty good at making things, so if you want to find a niche where you can add value outside of a large company you need to look for things that are not commercially attractive at scale.
One niche that might fit is local-first software. From the point of view of a large software company local-first software adds complexity, is easier to pirate and easier to migrate away from. So all the advances in local-first software right now are driven by individuals or small companies who are more UX-driven.
Half-arsed workflows
Here is how I produce invoices and contracts for consulting:
- Open an old invoice/contract in firefox.
- Use the inspector to change the values.
- Hit 'save as new file'.
Javascript vs serialization
In the browser it's common to want to take some work off the main thread to avoid blocking the UI. It's easy - just send the inputs to a webworker and send the output back.
What if the thing that you want to take off the main thread is serialization? Sending the object-to-be-to-serialized to a webworker recursively copies the whole object into the webworker memory space and then the result has to be copied back. This can end up blocking the main thread almost as long as the serialization itself would have.
Afaict the only solution for large objects is either SharedArrayBuffer + WebAssembly threads, or using async to break up the serialization into chunks.
Links
- Extensible Extension Mechanisms and Facets as Composable Extension Points. Marijn Haverbeke (the author of codemirror/prosemirror) has been thinking on how to balance extensibility and stability, and especially how to ensure that arbitrary extensions work together.
- JOIN: The Ultimate Projection explains the core intuition behind decorrelating subqueries. Everything else is just fiddly details.
- Andy Matuschak on being feral. Resonates - my twitter/github bio has been 'feral man-ape' for years because I don't want to present a polished self-image that I won't enjoy trying to live up to.
- My other database is a compiler. Using code analysis to convert typescript into mixed sql/typescript queries. They're still somewhat limited by the database interface being restricted sql - if they could run typescript functions directly inside the database in a V8 isolate then they could avoid the communication costs whenever they encounter a function that can't be translated to sql.
- Let's Remix Distributed Database Design!. Another TigerBeetle talk, mostly focused on how persistent distributed consensus can't be correctly handled by slapping raft on top of an existing storage engine, because storage faults can be byzantine.
- Design sketch for a gui library on top of mach. There's a frustrating problem in gui where at the point you are creating a widget you don't yet know how big later widgets will be, so you don't know how big this widget will be, so you don't know if it's under the mouse pointer. So usually either you give up on complex layouts (eg dear imgui) or you wait until the end of the frame to handle events (eg html dom) which requires callbacks which complicate memory management in non-gced languages. This library instead delays layout by a frame, so you get both complex layout and immediate-mode-style events, at the expense of sometimes having one-frame layout glitches when content resizes. It's not a tradeoff I've seen before.
- New directions in cloud programming. Announcing a research agenda following up on prior work at the BOOM lab. "Key to our approach is a separation of distributed programs into a PACT of four facets: Program semantics, Availablity, Consistency and Targets of optimization."
- Twenty Minutes of Reasons to Use the RemedyBG Debugger. Windows-only, unfortunately. But it's impressive to see that a single motivated person can compete with the Visual Studio debugger and win over veteran developers. Also nice to see more real-world examples of Dear ImGui.
- Pitfalls and bumps in Clojure's Extensible Data Notation. Something of a counterpoint to The shape of data - edn isn't well-specified enough to have multiple compatible implementations, and the
prmethod doesn't always produce valid edn. - Selling out is usually more a matter of buying in. Sell out, and you're really buying into someone else's system of values, rules and rewards. The so-called "opportunity" I faced would have meant giving up my individual voice...