I felt like I didn't do much this year, but now that I write it all down...
Streaming/incremental
streaming-consistency: 94 commits, 2952 insertions(+), 36 deletions(-)
I wanted to understand this whole space better.
The goal was to produce the high-level view that appears in An opinionated map of incremental and streaming systems.
At first I thought that the way to understand the tradeoffs between different systems would be to characterize them by performance on different workloads, like we do with databases. You can see the start of a plan for that in Thoughts on benchmarking streaming systems.
To fairly compare databases you have to benchmark them at the same consistency levels. But I found that none of the popular streaming systems had any documentation about consistency at all. Worse, when I was reading the implementations I didn't find any of the metadata that I expected to be used to enforce consistency. So I ended up testing consistency instead in Internal consistency in streaming systems.
I found that both flink (barring custom operators) and ksqldb have no concept of internal consistency at all, and that for many kinds of computations they will produce outputs that are not correct for any point in time, and often not even possible for any set of inputs.
(I also found what I suspect is a violation of eventual consistency in flink but the authors disagreed and the issue is now marked as stale.)
I didn't test noria, but I talked to the author and after some time struggling to reach shared terminology I think we're agreed that it will also exhibit the same kinds of internal consistency violations.
I never managed to produce output at all from kafka streams.
Only differential dataflow (and materialize) produced correct answers for my examples.
I investigated maybe 4-5 other systems but none of them could even express the examples, usually because they don't support non-windowed joins at all.
So this was pretty disappointing. I did get a much better understanding of the space, but the outcome was that almost nothing in the space is applicable to the kinds of database-esque problems I had in mind.
I had one last braindump in Thoughts on benchmarking before moving on.
Dida
dida: 212 commits, 7752 insertions(+), 37 deletions(-)
Differential dataflow was the only streaming system I found that can handle basic relational algebra in the presence of deletions and also guarantees correct answers.
Why isn't differential dataflow more popular? produced a lot of feedback. Much of it centered around differential dataflow being too hard to understand and use.
So I wrote dida, a simplified version of the same algorithms. It's still in a very alpha state, with few tests. But it is able to produce correct answers for the examples I used in the internal consistency investigations above. And the understanding I got from days poring over the dd code and papers is condensed in How dida works.
Dida also has javascript bindings, both natively in node and in the browser via wasm. They're barely tested and leak memory, but there are working examples for both.
Debugging dida is difficult. Symptoms appear very far away from the actual cause of the bug. Most of the intermediate state is multiversion indexes over multi-dimensional timestamps. Printlns just weren't cutting it. So I made my own little debugger which snapshots the state of the dataflow at every transition, augments each state with additional views, check for violations of invariants and allows stepping back and forth through the timeline in a nice gui.
This was my first time using dear imgui and I was blown away by how many orders of magnitude less time it takes to build dev tooling compared to trying to do the same on the web. I'm going to put guis on everything now.
Imp
imp: 95 commits, 3764 insertions(+), 2487 deletions(-)
bounded-live-eval: 496 insertions(+), 49 deletions(-)
relational-crdts: 5 commits, 251 insertions(+), 138 deletions(-)
Imp is a relational programming language.
I've been interested for a long time in blurring the lines between databases and programming languages, but the most recent motivation came from working on materialize. Writing a spec-compliant SQL engine made me realize what a fractally awful language SQL is, culminating this year in writing Against SQL.
I worked out much of the language design for imp last year. It can express roughly the same operations as SQL-92 DML, plus recursion, nested relations and first-class functions. But the grammar, denotational semantics and type system each fit on a single page, many queries are much easier to write and modify, and every imp program can still be compiled to a static graph of relational algebra operations.
The magic sauce (other than basics like non-insane name resolution) is to model functions as infinite sets. Then function application and subqueries are both just a kind of join. Most other relational operations can be expressed in terms of these two primitives, and if you can decorrelate every subquery then all the functions disappear and you can still compile to relational algebra.
(I also wrote a survey of decorrelation techniques in How Materialize and other databases optimize SQL subqueries.)
This year I made the syntax much more compact (as an aside - Better operator precedence), drastically improved the type system and added a live repl.
It's hard to convey how different it feels from a regular repl without using it yourself. Instead of inserting printlns and rerunning the code, I can just put the cursor on the expression I'm interested in and see every execution at that point.
(Unfortunately the only editor currently supported is one I wrote myself, which is probably difficult to build on any other machine. But most of logic is in imp.lang.Worker which should be easy to embed in other editors.)
I also spent some time on more challenging queries in Implicit ordering in relational languages. It's an interesting problem for incremental maintenance, and I think it also does a good job of showcasing how imp can be more compact than sql.
SQL:
with recursive
rightmost_child(id, parent_id) as (
select max(id), edit.parent_id
from edit
where edit.parent_id is not null
group by parent_id
),
rightmost_descendant(id, child_id) as (
select id, id
from edit
union
select parent.parent_id, child.child_id
from rightmost_child as parent, rightmost_descendant as child
where parent.id = child.id
),
rightmost_leaf(id, leaf_id) as (
select id, max(child_id) as leaf_id
from rightmost_descendant
group by id
),
prev_sibling(id, prev_id) as (
select edit.id, (
select max(sibling.id)
from edit as sibling
where edit.parent_id = sibling.parent_id
and edit.id > sibling.id
) as prev_id
from edit
where prev_id is not null
),
prev_edit(id, prev_id) as (
-- edits that have no prev siblings come after their parent
select edit.id, edit.parent_id
from edit
where not exists(
select *
from prev_sibling
where prev_sibling.id = edit.id
)
union all
-- other edits come after the rightmost leaf of their prev sibling
select edit.id, rightmost_leaf.leaf_id
from edit, prev_sibling, rightmost_leaf
where edit.id = prev_sibling.id
and prev_sibling.prev_id = rightmost_leaf.id
),
position(id, position, character) as (
-- root is at position 0
select edit.id, 0, edit.character
from edit
where edit.parent_id is null
union all
-- every other edit comes after their prev edit
select edit.id, position.position + 1, edit.character
from edit, prev_edit, position
where edit.id = prev_edit.id
and prev_edit.prev_id = position.id
)
select *
from position
order by position.position;
Imp:
rightmost_child: edits.?edit edit parent~ @ max;
fix rightmost_leaf: edits.?edit edit | edit rightmost_child rightmost_leaf @ max;
prev_sibling: edits.?edit edit parent parent~ .(?sibling edit > sibling) @ max;
prev: edits.?edit edit prev_sibling !! then edit prev_sibling rightmost_leaf else edit parent;
fix position: root, 0 | position ?edit ?pos edit prev~, pos+1;
edits ?edit (edit position), edit, (edit character)
This is especially true in the last approach in that article. The sql version uses arrays, which imp doesn't have. But imp is able to build abstractions over relations:
// functions for working with 'arrays'
insert: ?@sequence ?pos ?item
| pos, item
| sequence ?old_pos ?old_item
, old_pos + (old_pos >= pos then 1 else 0)
, old_item;
find_min_pos: ?@sequence ?@cond
sequence (?pos ?item cond pos item then pos) @ min;
The one fly in this beautiful ointment is that the old version of the codebase supported compiling to relational algebra, and the new version supports the live repl and other improvements this year, but I've yet to merge both sets of features. I've been procrastinating on it for almost a year. Maybe I have decorrelation ptsd.
Focus
focus: 99 commits, 2695 insertions(+), 1674 deletions(-)
Focus is a text editor that I wrote for myself. Much of the core was done at the end of 2020, but this year I added syntax highlighting, make mode, error squigglies, jump-to-error, async ripgrep and many other minor improvements and bugfixes.
I also started writing a series of articles explaining how it works (1, 2, 3) but I kind of lost interest. It just seemed less valuable than other things I wanted to write this year. Maybe in a few years once the code has settled down I'll try again.
When it came to syntax highlighting I looked around for some kind of reasoning about why highlighting works and how one should do it. I didn't find anything. Almost every editor highlights by token kind (ie one colour for keywords, one colour for functions, etc). I'm not sure that this is particularly useful, so instead I tried giving each token a hue that is determined by the token's hash.
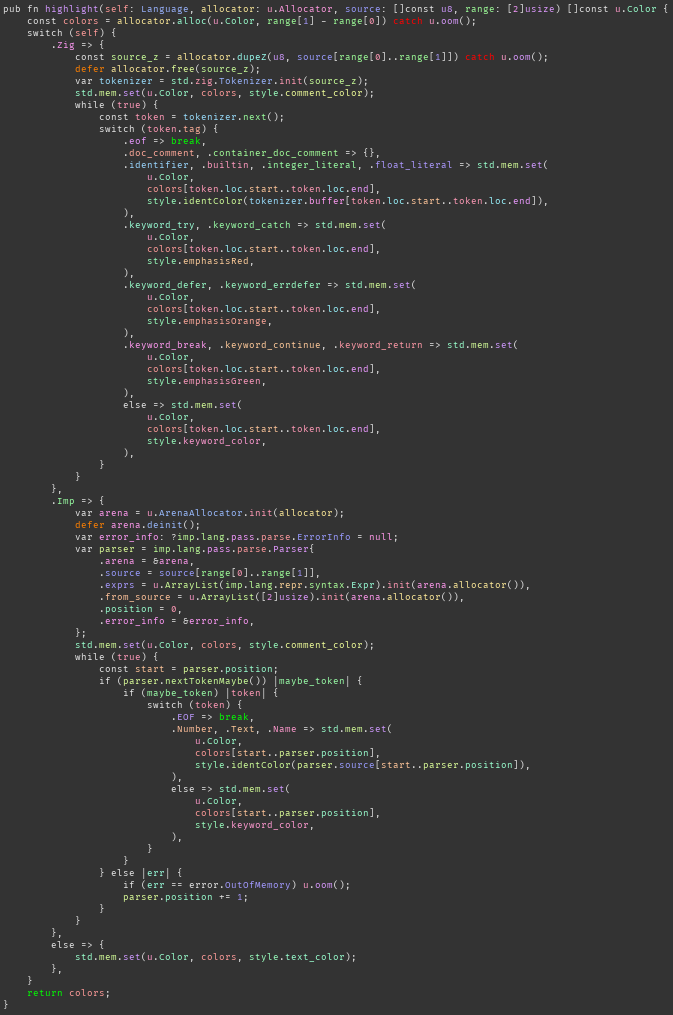
This does occasionally catch bugs where there are several lines with similar structure but I made a copy-paste bug.

You can also see in the bigger screenshot that control-flow keywords like catch, defer, break etc are brighter, so that they pop out when scanning the code, and this has definitely helped me spot several subtle bugs.
Focus is the text editor that I used for all of my writing and coding this year. In purely practical terms, it may not have been an efficient use of time. But it's hard to put a value on the satisfaction that I get from spending so much time in a world that I made.
Zig
Almost all of the code I've written this year has been in zig.
Everything I wrote last year in Assorted thoughts on zig (and rust) still holds.
Many of the metaprogramming problems I worked on this year, like the dida debugger and the dida javascript bindings, would have been much harder to solve in rust, maybe to the point that I just wouldn't have done it at all. Whereas metaprogramming in zig just feels like regular programming. (See Memory-mapped IO registers in zig for a taste). I just write the code that does the things that I want to happen. And if I mess it up I get a stack trace at compile time and I can insert compile-time printlns.
(By contrast, I spent most of a day in February trying to figure out how to get f64 to impl ExchangeData and eventually gave up.)
I've been enjoying the easy interop with c too. I'd never written c bindings in any language before, but in a year with zig I've used libgl, sdl, freetype, pcre2, the nrf52 sdk, node-api, sqlite3, microui, nuklear, dear imgui and implot. It doesn't feel like a big deal.
I'm still conflicted about security. I wrote How safe is zig?, thinking out loud. My position at the moment is that for the kinds of projects I'm working on right now the main risk is not that I'll have some serious vulnerability but that I'll never ship anything at all.
It's not just speed of development that matters either. In zig I spend more time thinking about my actual problem and less time being frustrated at my tools. I don't miss 10 minute incremental debug builds, forking crates to work around orphan rules, looking up how declarative macros work every time I use them, procrastinating on ever learning how to write procedural macros, repeatedly forgetting how lifetimes and associated types interact etc. Every speedbump breaks my flow and reduces my motivation, and motivation is my main bottleneck.
Reflections
This series of articles was the result of various conversations where I complained about how bad most online material about programming is and people encouraged me to write down my complaints. I was aiming for one short article but it got out of hand.
- Reflections on a decade of coding
- On bad advice
- Things unlearned
- Emotional management
- Setting goals
- Speed matters
- Moving faster
- Coding
- Testing
- Writing
I'm still very uncomfortable writing this kind of material, given how easy it is to be misleading or straight up wrong, but I keep getting emails from people who say they found it useful. I'll console myself that it's at least less bad than average.
HYTRADBOI
Late in the year I found myself accidentally organizing a conference called Have you tried rubbing a database on it?. I wrote about how that happened in Why start a new database conference?.
In the three weeks since the website was launched 596 people signed up to be notified when tickets are available. Of the speakers I invited, 12 said yes, 3 said maybe and only 2 haven't replied. Plus another 13 proposals have been submitted via the website and there is still 2 months to go until the submission deadline.
This is so much more than I was expecting and maybe also more than I'm actually prepared for. But I'll figure it out.
Sponsors
In January I signed up for github sponsors. I didn't expect it to be remotely successful, but Dan Luu spent several months convincing me that it was a worth a try.
He was right, I was wrong.
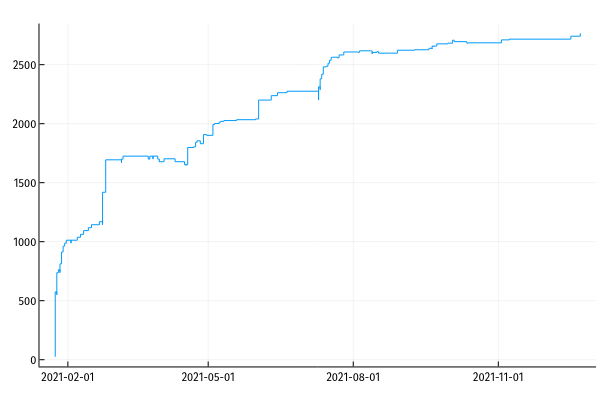
That came to ~27k CAD in 2020. If it stays at the current rate it will be ~33k CAD in 2021, which covers about 73% of my budget.
As a result of the sponsorship I spent a lot of time this year writing: 66757 words on this site and 21740 in my sponsors newsletter. That's a book!
Well over half the writing on this site was written this year. At least half of it is work I'm proud of. So I think we can call the sponsors project a success. Thanks to everyone who contributed.
Consulting
Right at the end of the year I started consulting for a company who are starting a new sql implementation.
I've turned down a lot of consulting requests in the last year because I want to have time and energy to focus on my own projects. This time I replied that I could probably only commit one day per month, thinking that they probably wouldn't be interested but that it didn't hurt to try. To my surprise they said yes.
So far it seems to be actually valuable, in that I can share all the mistakes I made at materialize and the things I would do differently if I were to do it again. If I can save them even a few engineer-days of wasted work each month then it ends up being a pretty good deal.
I've had a few similar requests in the last few months (mostly around streaming/incremental systems rather than sql) so I put up a page where people can pay to book a call. I'm not expecting anyone to just stumble across this and give me money, but if I can streamline the process then it reduces the cost of suggesting such an arrangement the next time someone emails me.
Office hours
I moved to Vancouver in 2019 the day before they entered their first lockdown. Between the pandemic isolation, moving to a new continent were I don't know anyone, and living for the first time in a city that is decidedly not a STEM hub, I've been starved of nerd talk.
So in the spirit of just trying things I put up a page where anyone can schedule a call. Three days later 12/15 slots are already booked. I have no idea how this will turn out, but I doubt I'll regret the experiment.
It is kind of strange to be simultaneously wanting to charge companies money for advice whilst also offering to talk to anyone for free. But I think people will probably do the right thing.
2022
The main theme of 2021 for me was unexpected success. Several friends have been trying to convince me that I am systematically underconfident. Whenever I've put that to the test by trying something that they've suggested and that I expect to fail, they've been right.
I'm not sure exactly how to recalibrate. But it's clear that I could benefit by just trying more things that I expect to fail, especially when the costs are low.
The sponsorship curve seems to have leveled off now, but there is very little churn. Together with the trickle of consulting I've signed up for I can comfortably cover my own expenses.
I might take on a little more consulting in 2022 because my wife has been waiting for a work permit since June 2021. Between covid and the Afghan refugee crisis the immigration office has built up a huge backlog so it probably won't arrive any time soon. It would be comforting to cover that gap.
I'm not sure what I'll work on next year. I don't know if it even makes sense to plan on that timescale. But I can think about what kinds of changes I'd like to see.
I want to spend less time reading blogs and forums and more time reading books and papers. When I was working at eve I spent an hour reading papers every morning, which added up to 200-400 papers per year. Much of my knowledge of databases was built on that backbone and I haven't updated it since. There is nothing on the frothy web that can offer that much value.
I'll maybe write less. The writing that I was happiest with this year was the result of deep technical work rather than quantity of writing. If in 2022 I could produce 3-4 pieces of work on par with the internal consistency investigation I'd be very happy.
I didn't write much code this year. Depending on what measure I use, I wrote between 2-8x as much code in the year that I worked at materialize. It's always frustrating that I don't manage to put the same kind of sustained efforts into things that I care about. I think the main difference is in having to decide what to do and maintain direction, vs working towards some pre-existing goal. I don't know how to create that same kind of certainty in my own work.
Working alone probably doesn't help either, but I don't think there is much likelihood of fixing that until the world approaches normal again.
I notice that I keep drifting towards working on things that are relevant for industrial software. These problems of scale and efficiency are what is legible and respectable, so it's easier to justify projects by appealing to that framing. But the problem is that I just don't care enough about industrial software development to actually finish the work.
I've always been much more inspired by ideas like end-user programming, tools for thought, convivial computing, malleable systems, scaling down and so on. And even then people want it to be justified in terms of how it will help users fulfill their role in the economy. But what I actually care about is that these machines were supposed to contain magic and we've made them boring.
So above all what I will keep in mind next year is to forget about the things that I think I'm supposed to care about and instead hunt for signs of magic.